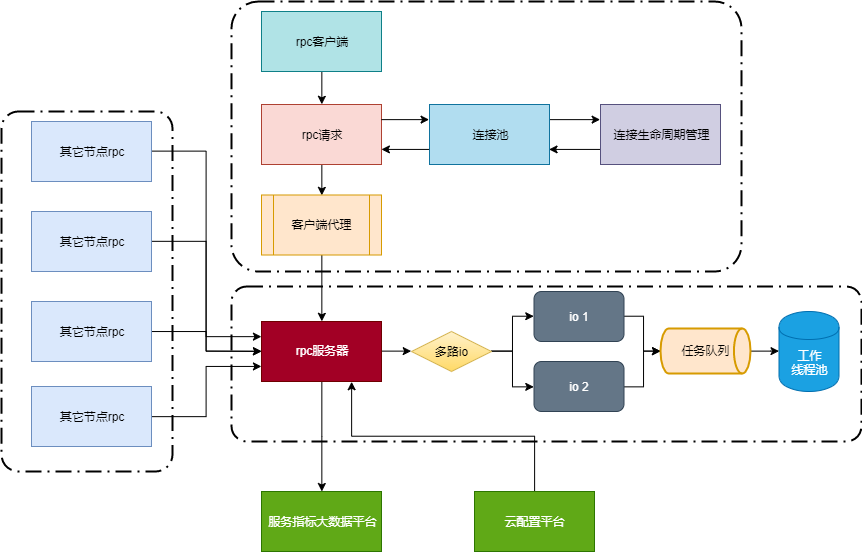
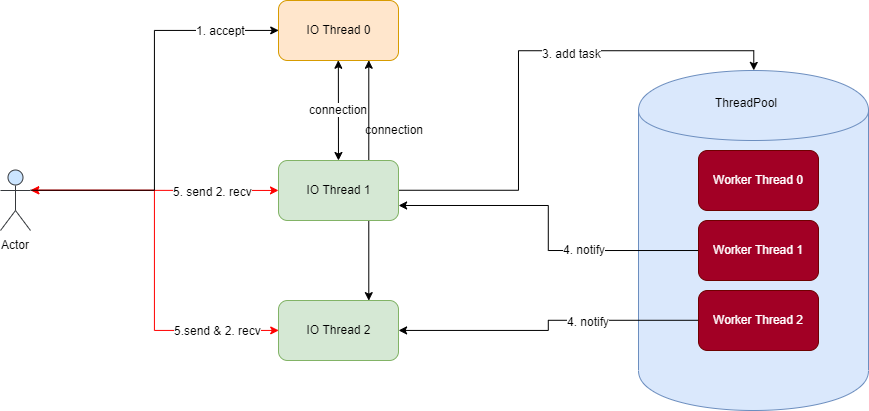
nghttp2技术实现
参考资料
https://datatracker.ietf.org/doc/html/rfc7540
https://www.nghttp2.org/documentation/
h2的优势:
- 性能更强:HTTP/2的多路复用技术,不仅可以减少连接次数,同时使用非阻塞I/O技术可以在一次握手过程中提高传输性能。
- 更强大的头部压缩:HTTP/2使用HPACK技术对头部信息进行压缩,可以有效减少传输的头部信息大小,从而节省带宽消耗。
- 服务端推送:服务器可提前将客户端可能需要的资源进行推送,从而可以减少客户端的重复请求,提升页面访问速度。
- 请求优先级:HTTP/2支持浏览器控制请求和响应的优先级,从而可以减少资源的加载时间。
- 更安全:HTTP/2默认使用HTTPS,可以有效防止中间人攻击,保障用户信息传输的安全性。