redis多级缓存
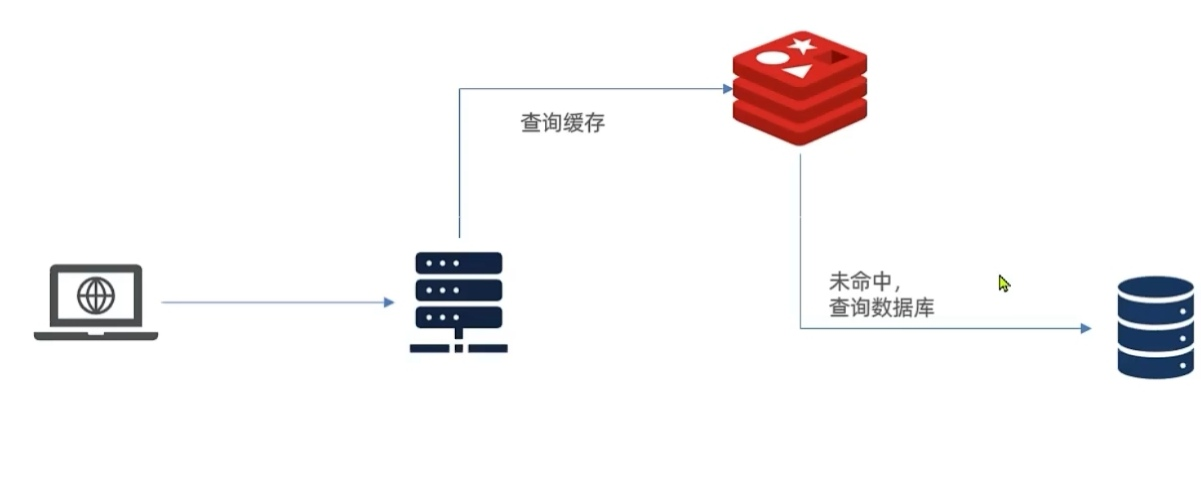
传统的缓存策略一般是请求到达 Tomcat 后,先查询 Redis ,如果未命中则查询数据库,存在下面的问题:
- 请求要经过 Tomcat 处理, Tomcat 的性能成为整个系统的瓶颈
- Redis 缓存失效时,会对数据库产生冲击
多级缓存方案
用作缓存的 Nginx 是业务 Nginx ,需要部署为集群,再有专门的 Nginx 用来做反向代理(proxy_pass+upstream配置):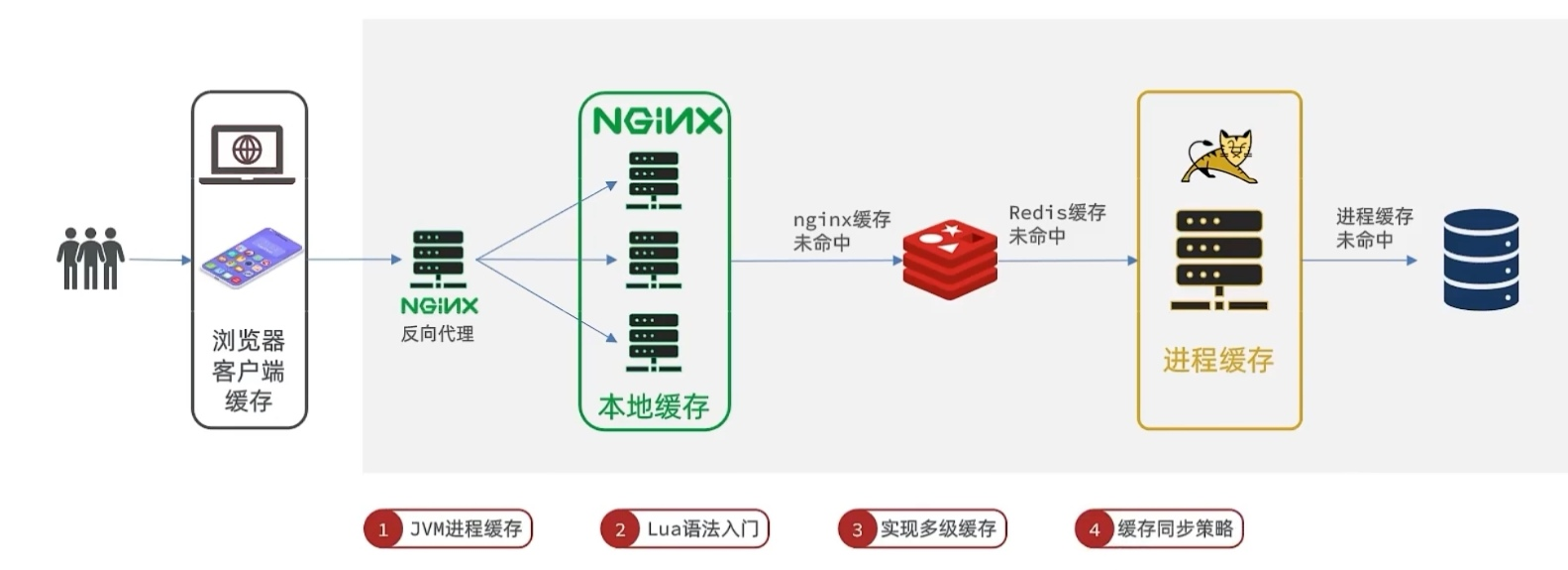
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如 Redis :
- 优点:存储容量更大、可靠性更好、可以在集群间共享.缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如 HashMap 、 GuavaCache :
- 优点:读取本地内存,没有网络开销,速度更快·缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine 提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
1
2
3
4// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为1
.build(); - 基于时间:设置缓存的有效时间
1
2
3
4// 创建缓存对象
Cache<String, String> cache = Caffeine.newButlder()
.expireAfterWrite(Duration.ofSeconds(10))//设置缓存有效期为10秒,从最后一次写入开始计时
.build(); - 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。



修改nginx.conf文件
1.在nginx.conf的http下面,添加对OpenResty的Lua模块的加载:
1 | #加载lua模块 |
2.在nginx.conf的server下面,添加对/api/item这个路径的监听:
1 | location /api/item { |
lua里面的假数据可以用ngx.say实现。

nginx提供了内部API用以发送http请求:
1 | local resp = ngx.location.capture("/path",{ |
返回的响应内容包括:
- resp.status :响应状态码
- resp.header :响应头,是一个table
- resp.body :响应体,就是响应数据
注意:这里的 path 是路径,并不包含 IP 和端口。这个请求会被 nginx 内部的 server 监听并处理。
但是我们希望这个请求发送到 Tomcat 服务器,所以还需要编写一个 server 来对这个路径做反向代理:
1 | location /path { |
我们可以把 http 查询的请求封装为一个函数,放到 OpenResty 函数库中,方便后期使用。
- 在/usr/local/openresty/lualib目录下创建 common.lua 文件:
1
vi /usr/local/openresty/lualib/common.lua
- 在 common.lua 中封装 http 查询的函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16--封装函数,发送 http 请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path, {method = ngx.HTTP_GET, args = params})
if not resp then
--记录错误信息,返404
ngx.log(ngx.ERR ,"http not found, path :", path, ", args :", args)
ngx.exit(404)
end
return resp.body
end
--将方法导出
local _M ={
read_http = read_http
return _M
}
OpenResty 提供了一个 cjson 的模块用来处理 JSON 的序列化和反序列化。官方地址:https://github.com/openresty/lua-cjson/
- 引入 cjson 模块:
1
local cjson = require "cjson"
- 序列化:
1
2
3
4local obj = {
name = 'jack', age =21
}
local json = cjson.encode(obj) - 反列化:
1
2
3
4local json ='{"name" : "jack", "age" : 21}'
--反序列化,变成table
local obj = cjson.decode(json);
print(obj.name)
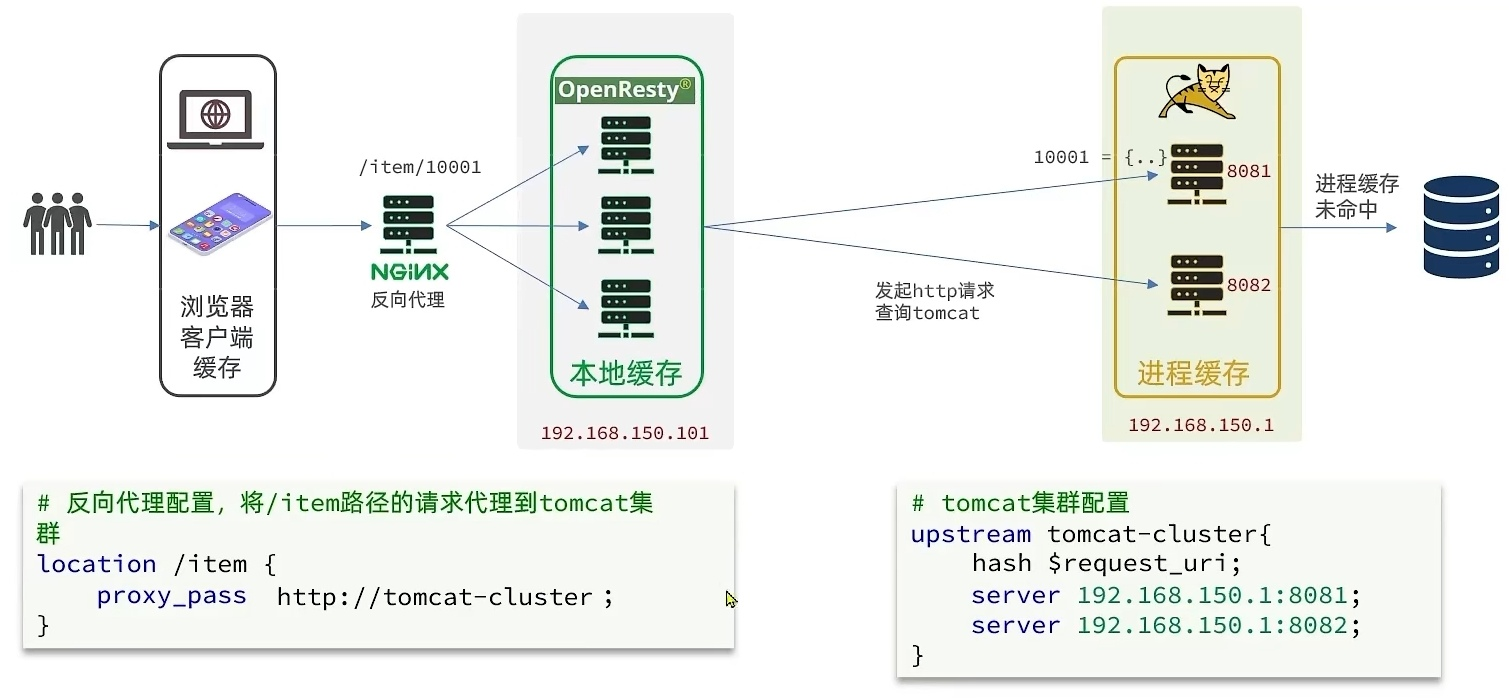
使用hash负载均衡,这样相同的请求会到同一台机器,进程缓存才能被利用起来。
冷启动:服务刚刚启动时, Redis 中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到 Redis 中。
OpenResty 提供了操作 Redis 的模块,我们只要引入该模块就能直接使用:
- 引入 Redis 模块,并初始化 Redis 对象
1
2
3
4
5
6--引入 redis 模块
local redis = require("resty.redis")
--初始化 Redis 对象
local red = redis:new()
--设置 Redis 超时时间
red:set_timeouts(1000, 1000, 1000) - 封装函数,用来释放 Redis 连接,其实是放入连接池
1
2
3
4
5
6
7
8
9
10--关闭 redis 连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time =10000 --连接的空闲时间,单位是毫秒
local pool_size =100
--连接池大小
local ok , err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR ,"放入 Redis 连接池失败:", err )
end
end
OpenResty 提供了操作 Redis 的模块,我们只要引入该模块就能直接使用:
- 封装函数,从 Redis 读数据并返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22--查询 redis 的方法,ip和 port 是 redis 地址, key 是查询的 key
local function read_redis(ip, port, key)
--获取一个连接
local ok , err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR ,"连接 redis 失败:", err )
return nil
end
--查询 redis
local resp , err = red:get(key)
--查询失败处理
if not resp then
ngx.log(ngx.ERR ,"查询 Redis 失败:", err ,", key =", key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR ,"查询 Redis 数据为空, key =", key)
end
close_redis(red)
return resp
end
查询商品时,优先 Redis 缓存查询
需求:
- 修改 item.lua ,封装一个函数 read_data ,实现先查询 Redis ,如果未命中,再查询 tomcat
- 修改 item.lua ,查询商品和库存时都调用 read_data 这个函数
1
2
3
4
5
6
7
8
9
10
11--封装函数,先查询 redis ,再查询 http
local function read_data(key, path, params)
--查询 redis
local resp = read_redis ("127.0.0.1", 6379, key)
--判断 redis 是否命中
if not resp then
-- Redis 查询失败,查询 http
resp = read_http (path , params)
end
return resp
end
OpenResty 为 Nginx 提供了 shard dict 的功能,可以在 nginx 的多个 worker 之间共享数据,实现缓存功能。
- 开启共享字典,在nginx.conf的http下添加配置:
1
2#共享字典,也就是本地存,名称叫做:item_cache ,大小150m
lua_shared_dict item_cache 150m;
操作共享字典:
1 | --获取本地缓存对象 |
缓存数据同步的常见方式有三种:
- 设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
- 同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
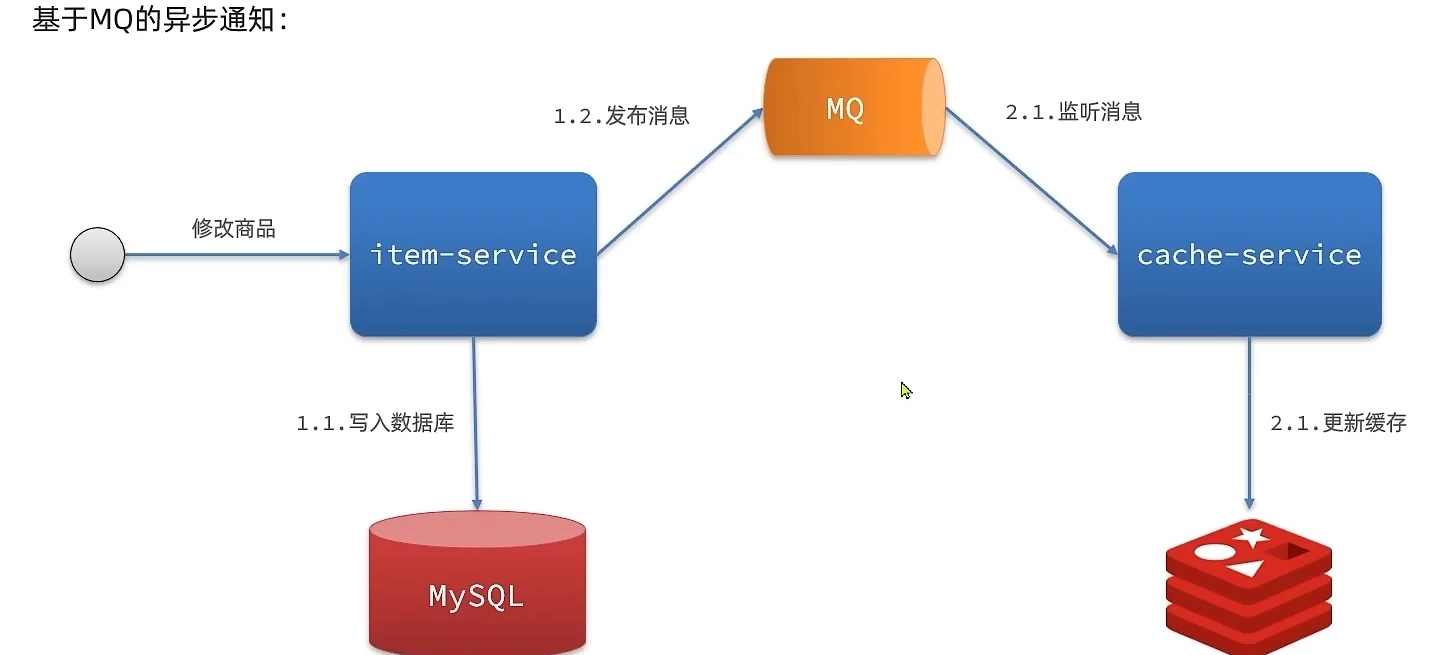
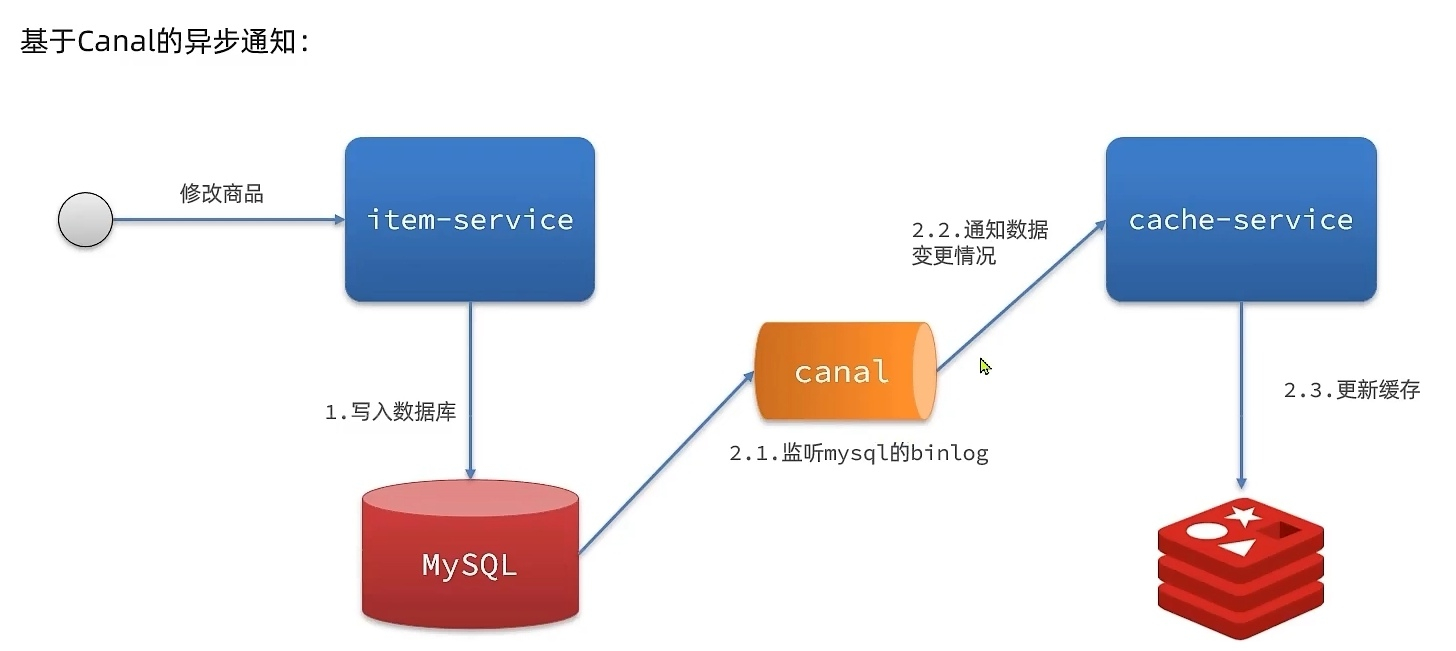
- 异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
Canal[ka’nael],译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。GitHub的地址:https://github.com/alibaba/canal
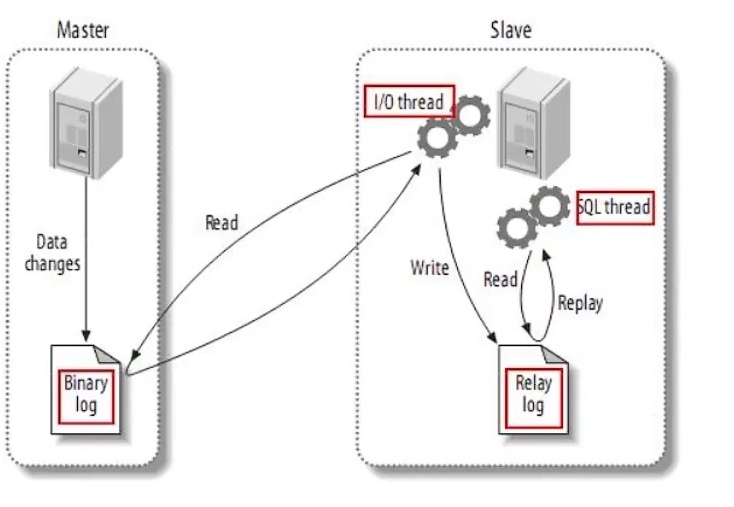
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
- MySQL master 将数据变更写入二进制日志(binary log),其中记录的数据叫做binary log events
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal 就是把自己伪装成 MySQL 的一个 slave 节点,从而监听 master 的 binary log 变化。再把得到的变化信息通知给 Canal 的客户端,进而完成对其它数据库的同步。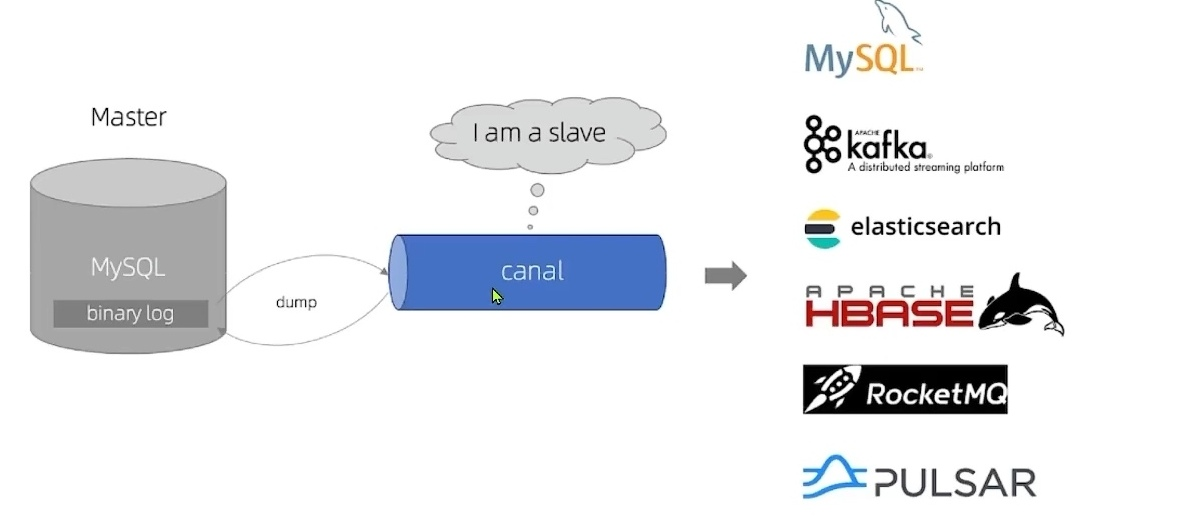
mysql主从同步配置
1 | log- bin =/var/lib/mysql/mysql-bin |
配置解读:
设置binary log存放地址和文件名。
指定对哪个 database 记录 binary log events ,这里记录 heima 这个库。
设置用户权限
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对 heima 这个库的操作权限。
1 | create user canal@'%' IDENTIFIED by 'canal' |
查看主从状态
1 | show Master status |
Canal 提供了各种语言的客户端,当 Canal 监听到 binlog 变化时,会通知 Canal 的客户端。不过这里我们会使用 GitHub 上的第三方开源的 canal-starter 。