udp可靠性传输设计之kcp
udp传输本身是不可靠的,要做到可靠性传输,需要参考tcp的原理在用户层进行修改,所以在可靠性设计之前,需要弄明白tcp传输的一些原理。
发送确认流程
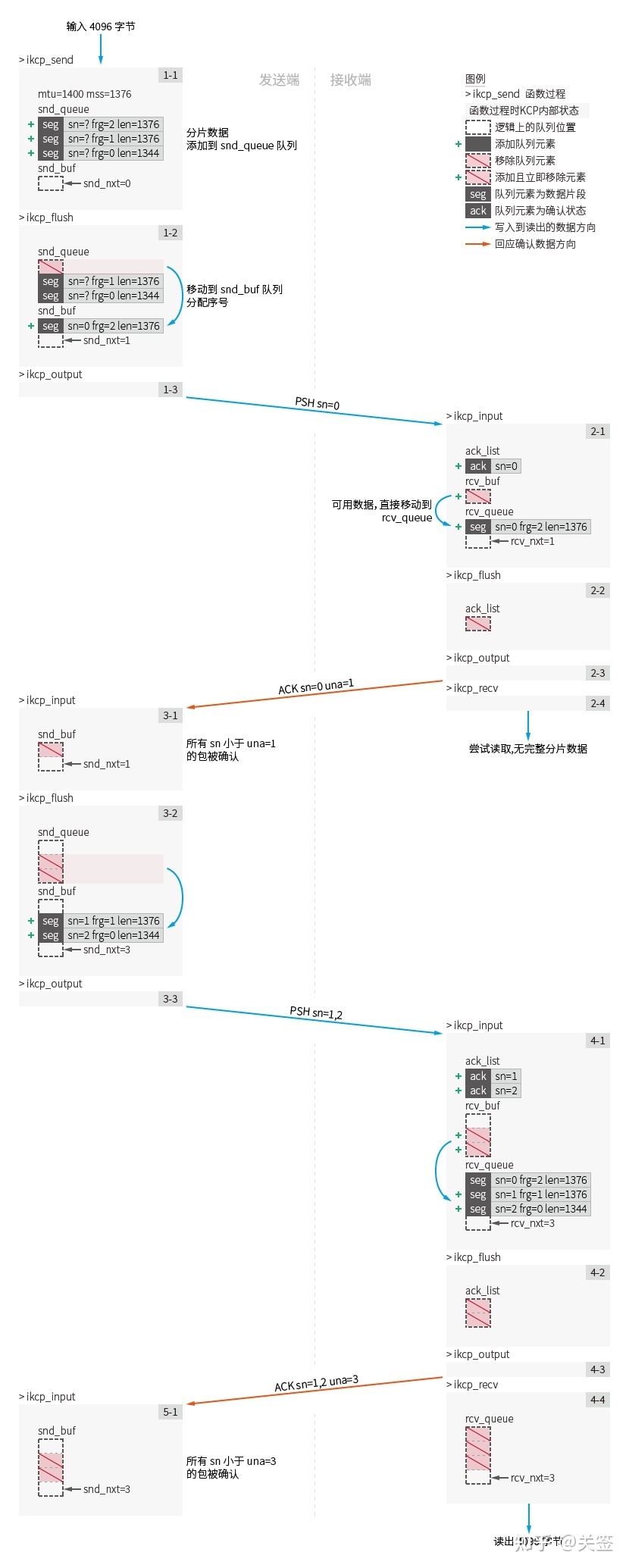
首次数据发送
对 k1 调用 ikcp_send: (图步骤 1-1)
向发送端写入了长度为 4096 的数据。依据 kcp.mss 被切割成三个长度为 1376/1376/1344 的包,每个包的 seg.frg 分片标记分别为 2/1/0。
kcp.mtu 最大传输单元 定义了 ikcp.output 回调每次收到的最大数据长度,默认为 1400。
1 | 示意图中 ikcp_output 方法最终会调用 ikcp.output 函数指针。(ikcp.c:212) |
kcp.mss 最大报文长度 由 kcp.mtu 减去协议开销 (24字节) 计算得来,默认为 1376。
此时不会执行任何 kcp.output 回调,所有分片数据均会分配并记录到 IKCPSEG 结构中,并追加到 kcp.snd_queue 队列 (ikcp.c:528)。
此时 k1 的 kcp.snd_queue 队列长度为 3,kcp.snd_buf 队列长度为 0。
对 k1 调用 ikcp_flush: (图步骤 1-2)
1 | 这里忽略窗口具体计算流程,只需要知道这里 k1 首次调用 ikcp_flush 时拥塞窗口 kcp.cwnd 的值为 1。 |
因为拥塞窗口限制, 所以首次发包仅能发送一个。将 kcp.snd_queue 队列首数据长度为 1376 的 IKCPSEG 对象被移动到 kcp.snd_buf 队列中 (ikcp.c:1028), 并且依据 kcp.snd_nxt 分配序号 seg.sn 的值为 0 (ikcp.c:1036), seg.cmd 字段为 IKCP_CMD_PUSH, 表示一个数据推送包。
此时 k1 的 kcp.snd_queue 队列长度为 2,kcp.snd_buf 队列长度为 1。
步骤 1-3 中对首次发送的数据执行 ikcp_output 调用 (ikcp.c:1113) 发送出数据包 [PSH sn=0 frg=2 len=1376]。
1 | 数据指令类型仅有四种: IKCP_CMD_PUSH (数据推送) IKCP_CMD_ACK (确认) IKCP_CMD_WASK (窗口探测) IKCP_CMD_WINS (窗口应答),定义在 ikcp.c:29 |
首次数据接收和数据读取
对 k2 调用 ikcp_input: (图步骤 2-1)
输入数据包 [PSH sn=0 frg=2 len=1376],进行解析包头以及合法性检查。(ikcp.c:769)
解析数据包的类型,进入数据推送分支处理。(ikcp.c:822)
记录数据包的 seq.sn 值和 seq.ts 值到确认列表 kcp.acklist 中 (ikcp.c:828), 请注意:这个示例中 seq.ts 的值永远为 0。
将接收的数据包添加到 kcp.rcv_buf 队列中。(ikcp:709)
对 kcp.rcv_buf 队列检查的首个数据包是否可用,若为可用的数据包,则移动到 kcp.rcv_queue 队列中。(ikcp.c:726)
对于 kcp.rcv_buf 中的可用的数据包定义为:期望接收的下一个数据序号 (取自 kcp.rcv_nxt,这里下一个数据序号应该为 seg.sn == 0) 且 kcp.rcv_queue 队列的长度小于接收窗口大小。
此步骤中直接将 kcp.rcv_buf 队列唯一的数据包直接移动到了 kcp.rcv_queue 队列。
此时 k2 的 kcp.>rcv_queue 队列长度为 1,kcp.snd_buf 队列长度为 0。下一个接收数据序号 kcp.rcv_nxt 的值从 0 更新到了 1。
对 k2 调用 ikcp_flush: (图例步骤 2-2)
在 k2 的首次 ikcp_flush 调用中。因为确认列表 kcp.acklist 中有数据,所以会编码确认包并发送出 (ikcp.c:958)。
其中确认包中的 seg.una 值被赋值为 kcp.rcv_nxt=1。
这个包记为 [ACK sn=0 una=1]:表示在 ack 确认中,包序号 0 被确认。在 una 确认中,包序号 1 之前的所有包都被确认。
步骤 2-3 中调用 kcp.output 发出数据包。
对 k2 调用 ikcp_recv: (图步骤 2-4)
检查 kcp.rcv_queue 队列中是否含有 seg.frg 值为 0 的的包 (ikcp.c:459),若含有此包,则记录首个 seg.frg==0 的包以及此包之前的包的数据总长度作为返回值返回。若没有则此函数返回失败值 -1。
因为此时 kcp.rcv_queue 仅有包 [PSH sn=0 frg=2 len=1376],所以尝试读取失败。
1 | 如果是流模式下 (kcp.stream != 0), 所有的包都会被标记为 seg.frg=0。此时 kcp.rcv_queue 队列有任何包,都会被读取成功。 |
首次数据确认
对 k1 调用 ikcp_input: (图步骤 3-1)
输入数据包 [ACK sn=0 una=1]。
UNA确认:
收到的任何包都会先尝试进行 UNA 确认 (ikcp.c:789)
通过确认包的 seg.una 值确认并移除了所有 kcp.snd_buf 队列中 seg.sn 值小于 una 值的包 (ikcp:599)。
[PSH sn=0 frg=2 len=1376] 在 k1 的 kcp.snd_buf 队列中被确认并移除。
ACK确认:
解析数据包的类型,进入确认分支处理。(ikcp.c:792)
对确认包的序号进行匹配并移除对应的包。(ikcp.c:581)
在步骤 3-1 执行 ACK 确认时,kcp.snd_buf 队列已经为空,因为唯一的包 [PSH sn=0 frg=2 len=1376] 预先被 UNA 确认完毕。
若 kcp.snd_buf 队列头部数据发生了确认 (kcp.snd_una 发生了变化),此时重新计算拥塞窗口大小 cwnd 值更新为2 (ikcp.c:876)。
UNA / ACK 确认示意图, 此图额外记录了流程示意图中未标记的 kcp.snd_una 的状态:
对于顺序到达的确认包,ACK 确认不会起作用。对于乱序到达的包,通过 ACK 确认后单独移除此包: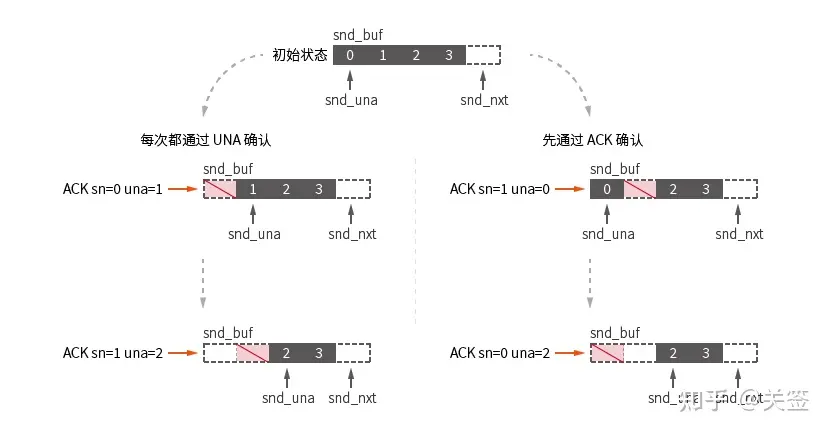
二次数据发送
对 k1 调用 ikcp_flush: (图步骤 3-2)
正如步骤 1-2 一样,新的拥塞窗口 kcp.cwnd 的值已经被更新为 2,此次会发出剩余的两个数据包: [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344]。
步骤 3-3 中实际会调用两次 kcp.output 分别发出数据包。
二次数据接收和数据读取
对 k2 调用 ikcp_input: (图步骤 4-1)
输入数据包 [PSH sn=1 frg=1 len=1376] 和 [PSH sn=2 frg=0 len=1344]。
每个包被添加到 kcp.rcv_buf 队列中,其都是可用的,最终全部被移动到 kcp.rcv_queue 队列。
此时 k2 的 kcp.rcv_queue 队列长度为 3,kcp.snd_buf 长度为 0。预期接收的下一个包 kcp.rcv_nxt 的值从 1 更新到了 3。
对 k2 调用 ikcp_flush: (图步骤 4-2)
kcp.acklist 中的确认信息会被编码为包 [ACK sn=1 una=3] 和 [ACK sn=2 una=3] 在步骤 4-3 发送。
实际上这两个包会被写入一个缓冲区然后进行一次 kcp.output 调用。
对 k2 调用 ikcp_recv: (图步骤 4-4)
现在 kcp.rcv_queue 中有三个未读取的数据包: [PSH sn=0 frg=2 len=1376] [PSH sn=1 frg=1 len=1376] 和 [PSH sn=2 frg=0 len=1344]
此时符合读取到一个 seg.frg 值为 0 的包,计算可读取总长度为 4096。继而会全部读取三个包中的数据写入读取缓冲区并返回成功。
需要注意另一种情况: 若当此时 kcp.rcv_queue 队列中含有 seg.frg 值为 2/1/0/2/1/0 的 2 次用户发送包被分片成 6 个数据包时,对应的也需要调用 2 次 ikcp_recv 来读出全部收到的完整数据。
二次数据确认
对 k1 调用 ikcp_input: (图步骤 5-1)
输入确认数据包 [ACK sn=1 una=3] 和 [ACK sn=2 una=3],解析到 seg.una=3 时。包 [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] 从 kcp.snd_buf 队列中通过 una 确认完毕并移除。
所有发送的数据均已被确认。
队列与窗口
窗口 用于流量控制。它标记了队列逻辑上的一段范围。由于队列因为实际数据的处理,位置不断向序号高位移动。逻辑上此窗口也会不断移动,同时也会伸缩大小,所以也被称为 滑动窗口 (Sliding window)
此示意图为 “基本数据发送与接收流程” 小节中流程示意图步骤 3-1 至步骤 4-1 的另一种表现形式。作为步骤范围外的操作,数据方向均以半透明的箭头表示。
所有数据通过箭头指向的函数处理前往新的位置 (两倍大图):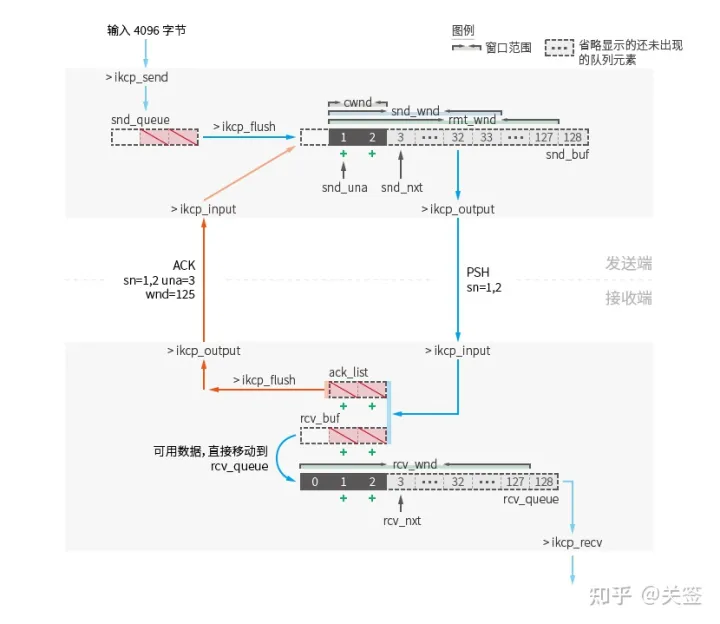
snd_queue 发送队列
发送端 ikcp_send 函数传入数据,会经过数据切片处理后直接存入 kcp.snd_queue 发送队列中。
每次调用 ikcp_flush 时。会依据发送窗口大小 kcp.snd_wnd 和远端窗口大小 kcp.rmt_wnd 以及拥塞窗口大小 kcp.cwnd 来计算此次发送的窗口大小,其值为三者最小值: min(kcp.snd_wnd, kcp.rmt_wnd, kcp.cwd) (ikcp.c:1017)。
若通过 ikcp_nodelay 函数将 nc 参数设置为 1 通过关闭控流模式,忽略计算拥塞窗口的值。发送窗口的计算结果就是 min(kcp.snd_wnd, kcp.rmt_wnd) (ikcp.c:1018)。
在仅关闭控流模式的默认配置下,首次可发送的数据包数量为 kcp.snd_wnd 的默认大小值 32。这与基本收发流程示例中不一样,示例中首次仅能发出一个包,因为默认开启了控流。
新增发送的数据包会被移动到 kcp.snd_buf 队列。
对于 ikcp_send 的数据仅有切片上限127的限制 (即 127*kcp.mss=174752 字节)。对于处于发送队列中数据包的总数量没有任何限制。见: 如何避免缓存积累延迟
snd_buf 发送缓冲区
kcp.snd_buf 发送缓冲区中存储了即将或者已经发送过的数据。
每次调用 ikcp_flush 时,计算此次发送窗口并且从 kcp.snd_queue 移动数据包到当前队列后。对当前队列所有数据包会有三种情况的处理:
- 首次数据发送 (ikcp.c:1053)
包被发送的次数会被记录在 seg.xmit 中,首次发送的处理比较简单,会初始化一些用于重传超时的参数 seg.rto / seg.resendts。 - 数据超时 (ikcp.c:1058)
当内部记录的时间 kcp.current 超过包本身的超时时间 seg.resendts 时,发生超时重传。 - 数据跨越确认 (ikcp.c:1072)
当数据端被跨越确认,跨越次数 seg.fastack 超过了跨越重传配置 kcp.fastresend 时,发生跨越重传。(kcp.fastresend 默认为 0 ,为 0 时计算为UINT32_MAX, 永远不会发生跨越重传。) 发生超时重传后会重置当前包 seg.fastack 为 0。
ack_list 确认列表
确认列表是一个简单的记录列表,它原始地按照包的接收顺序记录序号和时间戳 (seg.sn / seg.ts)。
1 | 因此在本文的示意图中 kcp.ack_list 都不会有任何留白的元素位置画出。因为它不是一个逻辑上有序的队列 (同理,虽然在 snd_queue 队列中包还未分配序号,但其逻辑上其序号已经确定)。 |
rcv_buf 接收缓冲区
接收端中缓存暂时无法处理的数据包。
ikcp_input 传入的所有数据包均会优先到达此队列, 同时会按照原始到达顺序记录信息到 kcp.ack_list。
只有两种情况数据会依旧滞留在此队列中:
- 数据包的序号发生了丢包或乱序:
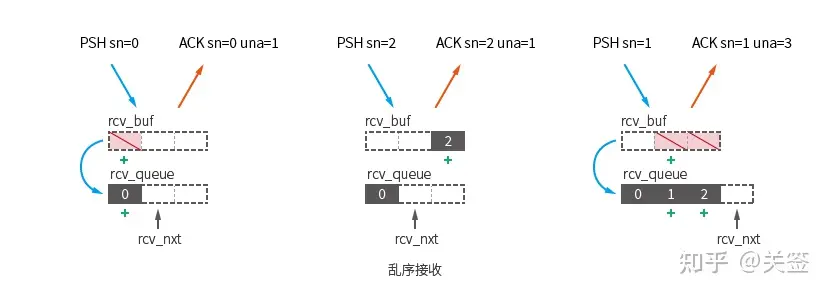
这里先收到了包 [PSH sn=0],符合可用包的条件,移动到 kcp.rev_queue。
紧接着收到了包 [PSH sn=2],不为期望接收的下一个包 (seg.sn == kcp.rcv_nxt), 导致此包滞留在 kcp.rcv_buf 中。
收到包 [PSH sn=1], 移动滞留的两个包 [sn=1] [sn=2] 到 kcp.rcv_queue。 - 接收窗口已满: kcp.rcv_queue 接收队列长度达到了接收窗口大小 kcp.rcv_wnd (未及时调用 ikcp_recv)。
rcv_queue 接收队列
接收端中存储了可被上层读取的数据。
在流模式下会读取所有可用数据包,在非流模式下会读取分片数据段并组合成完整的原始数据。
读取完成后会尝试从 kcp.rcv_buf 移动数据到此队列中 (可能是从满接收窗口状态中恢复)。
snd_wnd/rmt_wnd 发送窗口/远端窗口
发送窗口 kcp.snd_wnd 值是一个配置的值,默认为32。
远端窗口 kcp.rmt_wnd 是发送端收到接收端的包时 (不仅只是确认包) 会被更新的值。它记录的是当前数据包被接收端发送时, 接收端接收队列 kcp.rcv_queue 的可用长度 (ikcp.c:1086),初始值为 128。
cwnd 拥塞窗口
拥塞窗口是通过计算的值,在每次通过 ikcp_input 收到数据时会按照算法来增长。
若在刷出数据 ikcp_flush 时检测到遇到丢包和快速重传则按照算法重新计算。
1 | 初始化 kcp.cwnd 的位置为 1 时的位置在首次 ikcp_update 时对 ikcp_flush 调用中。 |
rcv_wnd 接收窗口
接收窗口 kcp.rcv_wnd 值是一个配置的值,默认为128。它限制了接收队列 kcp.rcv_queue 的最大长度。
拥塞控制和重传
在本小节中,提供了一个基于”基本数据发送与接收”小节示例代码改进的版本 kcp_optional.c,可以通过修改宏定义来进一步观察协议行为。
示例代码通过指定向 k1 写入指定次数的固定长度数据后,并完整地在 k2 中读出后,结束流程。
提供了宏来控制指定的功能:
- KCP_WND : 发送与接收窗口大小。
- KCP_THRESH_INIT : 慢启动阈值初始值。
- KCP_NODELAY : 指定 ikcp_nodelay 的四个参数: nodelay, interval, resend, nc。
- SEND_DATA_SIZE : 指定了每个周期向 k1 写入的数据长度。
- SEND_STEP : 指定了总的发送数据次数。
- TIME_INCREMENT : 指定了每次周期增加的逻辑时间。
- K1_DROP_SN / K2_DROP_SN: k1 或者 k2 丢弃指定序号的包。例如 0,0 就是连续丢弃序号 0 的包两次。-1 关闭此功能。
- ACK_DELAY_FLUSH : 启用此宏来延迟发送确认包。
- RECV_TIME: 接收端 k2 在此时间之后才读取数据包。
拥塞窗口计算
拥塞窗口通过 kcp.cwnd 和 kcp.incr 的值来记录。由于 kcp.cwnd 记录的单位为包,需要额外的 kcp.incr 来记录以字节长度为单位表示的拥塞窗口。
与 TCP 一样,KCP 拥塞控制也分为慢启动和拥塞避免两个阶段:
拥塞窗口增长
在确认数据包的过程中,每次 kcp.snd_buf 队列头部数据发生确认时 (有效 UNA 确认, kcp.snd_una 发生变化时)。且拥塞窗口小于记录的远端窗口 kcp.rmt_wnd 时,进行拥塞窗口增长。(ikcp:875)
1.若拥塞窗口小于慢启动阈值 kcp.ssthresh 时,处于慢启动阶段,此时拥塞窗口增长相对激进。拥塞窗口增长一个单位。
2.若拥塞窗口大于等于慢启动阈值时,处于拥塞避免阶段,拥塞窗口增长相对保守。若 kcp.incr 每次增加 mss/16 时,需要 16 个有效 UNA 确认后才增长一个单位拥塞窗口。实际的拥塞避免阶段窗口增长为:
1 | (mss * mss) / incr + (mss / 16) |
由于 incr=cwnd*mss 即:
1 | ((mss * mss) / (cwnd * mss)) + (mss / 16) |
等价于:
1 | (mss / cwnd) + (mss / 16) |
拥塞窗口进行每 cwnd 个和每 16 个有效 UNA 确认的叠加增长。
tcp可靠性传输
tcp传输有一些机制可以保证可靠性传输:
- ack机制,对方收到消息后会回应ack,当然有几种回应的方式,第一种就是收到一条回复一条,发送方需要收到上一条消息的ack后才能继续发送下一条消息,这种效率比较低,另一种是,连续发送多条消息,只需要回应一个ack即可,ack里面有序列号,代表这个序号之前的消息都接收到了,这个序列号也叫una,如果接收到的消息为1-2-3-5-6,丢失了4,那4-5-6都需要被重传,还有一种回应ack的方式是除了给出una,还给出了acklist,如果接收到的消息为1-2-3-5-6,那una是4,acklist是5-6,这样就可以实现选择性重传,发送方只需要重传4即可。这其实也就是ARQ的三种协议,书面语叫停等式、回退n帧、选择性重传。
- 序号机制,发出的消息都是带有seq序号的,这个在tcp的包头里面有一个序列号的字段专门用来表示序列号。
- 重排机制,有了序列号,接收方在接到数据后就可以做出排序处理,因为数据并不一定是有序到达接收方的,如只到了1-2-4,那要等待3的数据到来再插入到3的位置,这样排序好的数据才能给应用层使用。
- 窗口机制,这个主要用来限制发送方的发送速率,如果接收方没有剩余窗口可以接收新的数据了,那么发送方就不能继续发送数据了,否则数据会丢失,发送方也会定期去询问接收方是否有新的窗口可以接收数据了,一旦有了,就可以继续发送,因为接收方recvbuf里面的数据被应用层处理后,就会被删除,这时就有更多的窗口空间了。
kcp的优势
为什么有了tcp,还要设计可靠性udp传输呢?主要是为了传输的实时性,tcp当初的设计初衷就是要最大化的利用好带宽,实时性是次要的,所以才有慢启动环节,因为在当初带宽显得更重要,而kcp则利用tcp的10%-20%的带宽换取其30%-40%的传输速度,主要哪些方面可以提升速度呢?
- 重传的时机更快,tcp在丢包后,分别在2RTO、4RTO、8RTO、16RTO重传,而kcp可以选择1.5被的时间进行增长,数据可以更快的传输出去。
- 延迟ack,tcp为了更好的利用带宽,对接收到的数据做了延迟ack的处理,这样可以少发ack包,但是如果有出现丢包的情况,则比较慢才能发现,kcp是可以选择是否延迟ack,这样实时性更高。
- tcp可以快速重传,即在连续几次收到同一个ack后,说明数据有丢失,则这个ack序号后面的数据都要重传,如果要做到选择性重传,需要发送方接收方都开启tcp_sack参数,而kcp由于是una+ack机制,可以支持选择性重传,也支持快速重传。
- kcp没有慢启动机制,遵循公平竞争的原则,争取最快的把数据发送出去。
kcp重传机制
ARQ(自动重传请求)模型有两种响应类型:UNA(此编号之前的所有段已接收,类似于TCP)和ACK(已接收具有此编号的段)。例如,发送方发送1、2、3、4、5,而接收方收到1、2、4、5。对于UNA,所有段都将进行重新传输,即当接收到4、5时,接收方将两次回复UNA 3,发送方将重新传输3、4、5。如果仅使用ACK,代价太大了,接收方将为每个接收的段回复ACK 1、2、4、5。KCP使用更好的UNA和ACK模型,每个段都使用UNA,但在段丢失时会有ACK段。
TC操作的命令
tc qdisc add dev eth0 root netem delay 50ms 30ms loss 5%
这句的意思是给网卡eth0加上 50ms的延时,± 30ms 的抖动,在加 5%的丢包率
kcp调优指南
第一,你的数据量大了,默认的发送和接收窗口太小,远小于tcp的sndbuf rcvbuf量,需要调大,比如都调节为原来的4-5倍,这样可以提高数据量的并发性,避免累积。
第二,尝试减少数据量比如每次0.5k
第三,每次发送完调用flush,把数据刷出去,否则要下次update才出的去,你一次100k的数据按照mtu分成一百个包,窗口又小,积累严重不说,发送还要到下一轮。
第四,可选择公网高峰期测试
第五,调高udp的SNDBUF,RCVBUF
即便不丢包也不可能比tcp慢,即便0%-5%的丢包,tcp也照样无法体现出优势来,问题有几个:
你可以注意查看,ikcp_waitsnd 来查看发送队列是否还有等待,如果有,就继续调大发送窗口。
设置了快速模式以后,手工将:kcp->rx_minrto = 5,或者更小
udp是工作在interval模式下的,而tcp是工作在 epoll模式下的,有数据不用等待到下一个1毫秒。将udp也放入poll,一旦收到数据包,立马 ikcp_input 然后while循环ikcp_recv/ikcp_send,然后再掉一次update,数据基本没有停留的机会。
可以尝试放到公网测试,关闭模拟丢包。
kcp源码剖析
来看一下kcp的源码是怎么实现udp可靠性传输的。
核心的几个函数是ikcp_create、ikcp_update、ikcp_flush、ikcp_input、ikcp_recv、ikcp_send,其中ikcp_create只是创建kcp对象,比较简单,ikcp_update是需要定期调用的,根据外部传入的时钟current决定是否调用ikcp_flush。
1 | // 1. 创建 KCP对象: |
ikcp_flush主要是调用ikcp_output来发送一些数据,这个ikcp_output其实是调用的kcp对象的output方法,这个方法是需要用户自己实现的,通过ikcp_setoutput设置该方法。主要发送一些ack,是否需要询问远端窗口大小,以及是否需要发送本端窗口大小,将数据从snd_queue中移到snd_buf中,然后发送snd_buf里面的第一次需要传输的数据,和已经需要超时重传(如果设置了nodelay,超时重传由2rto变为1.5rto)或者快速重传的数据(如果超时重传不满足而快速重传(有包被跳过了次resent未成功发送)满足,也会重传),发送的时候不是一个包一个包发送,而是放在一起,如果马上要超过了mtu,则立马先发一次。
1 | struct IKCPSEG |
ikcp_input是在udp接收到数据之后对数据进行解析处理,解析出una信息后会删除的snd_buf里面所有sn小于una的包,una代表所有sn小于una的包接收端都接收到了,所以发送端可以删除了。
1 | // ikcp_parse_una |
接收到的消息类型分为四种:
- IKCP_CMD_ACK,这个代表发送消息后对端给出的回应,收到该类消息后代表之前发的sn包已经被接收了,所以也可以从snd_buf中删除sn的包了,同时由于回复的ack包里面还包含了ts时间戳,所以可以计算rtt来更新rto,并把ack包的最大sn计算出来,如果该最大值大于snd_buf中包的sn,说明有跳过一些包没有发送成功,即有丢包现象。
- IKCP_CMD_PUSH,这个代表发送端有发送数据包过来,需要先把该包里面的sn记录下来放到acklist里面去,因为收到包以后后面需要回复ack进行确认,如果接收到的包的sn没有超过rcv_next+rcv_wnd,即接收窗口还够的话,就把它放在rcv_buf中排好序的位置(如果已经有该sn的包了则丢弃),最后把rcv_buf里面的数据迁移到rcv_queue里面去,供应用程序读取,如果当前recv_queue还有空间(上一次满了),则下次ikcp_update时告诉远端那边本地窗口的大小(不再为0了,可以继续发数据了)。
- IKCP_CMD_WASK,远端想询问本地窗口的大小,给probe变量置上IKCP_ASK_TELL的标志,下次ikcp_update时应该判断该标志来告诉对方本地的窗口大小即可。
- IKCP_CMD_WINS,不做处理,这是远端告诉本地远端它的窗口大小,在上面已经解析出来了,已经存在rmt_wnd变量里面。
ikcp_send是上层用户调用的接口,这个比较简单,只是把要发送的数据根据mss分包后放入到snd_queue里面去,如果是流模式,数据比较大的话,还要设置包的frg字段,代表是第几个包,从高到低,最后一个是0代表是最后一个包了。甚至开始时如果上次snd_queue里面最后一个包没有达到mss,还要将本次数据取出一部分进行填充,剩下的数据才是进行frg再分包处理,这样把发送效率也用到了极致,发送过程中也不会被再分包。
ikcp_recv就是上层用户从rcv_queue里面接收数据了,首先看一下rcv_queue里面有多少数据,需要是完整的kcp包,如果frg是3(整包有3+1个包),但是rcv_queue里面只有3个数据包,说明没有接收完,所以要统计到frg等于0时有多少的数据量peeksize,如果你要读取的数据量比统计出来的数据量peeksize要小,这是不允许的,说明你没有把完整的一个kcp包读完,如果都没有问题,就可以把完整的kcp包数据读到buffer里面了,读完就可以删除recv_queue里面的包了,如果是peek模式则可以不删除(即ikcp_recv传入的大小是负数时),由于rcv_queue被腾出位置来了,所以可以把rcv_buf里面的包移到rcv_queue来了,如果读取数据之前rcv_queue是满的,从rcv_buf移数据到rcv_queue后rcv_queue还有空间,就可以在下次ikcp_update时告诉对端我方有窗口可以继续发送数据过来了。
总的来说,就是用户有数据要发送就先调用ikcp_send将数据分包先发送到snd_queue里面去,在程序下次调用ikcp_update时就会把数据调用output的接口发送出去,如果网络io接收到了新数据,需要用户先调用ikcp_input进行解析处理,处理后的数据会放入rcv_queue里面等待用户读取,所以用户需要调用ikcp_recv读取kcp完整包数据,这就是这几个核心函数参与的主要流程,也构成了kcp实现的核心思想。
通过阅读kcp的源码,也进一步加深了对tcp的理解,佩服kcp的作者能自己实现一个ARQ自动重传请求的协议来,这样的事算是一件很有意义的事,也是积累自己在行业的名声,与之学习。