io-cpu-mem
mem
读取文件:/proc/meminfo
MemTotal: 总内存
freeMem: Cached + MemFree + Buffers
程序占用mem:/proc/%d/status
VmRSS: 进程占用内存
cpu
读取文件:/proc/stat
包括:系统cpu、空闲、io等待、irq中断、软中断等。
1 | fscanf(file, "%s%lld%lld%lld%lld%lld%lld%lld%lld%lld", temp, &user, &nice, &sys, &idle, &iowait, &irq, &softirq, &steal, &guest); |
我们通过 iostat工具可以看到这几个状态的值,它们都是以百分比的形式显示的,CPU 是在这几个状态之间切换,所以这几个值总和是 100%: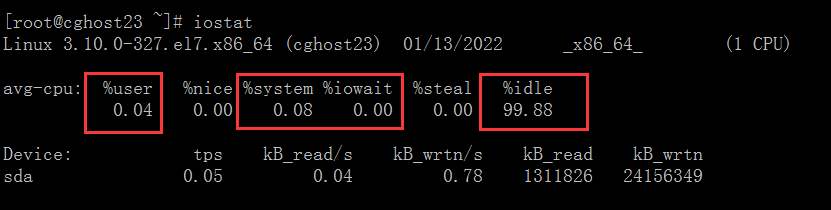
需要说明一点,上图中的 %sys, %user, %idle, %iowait 的百分比值都是针对所有的 CPU 来说的,统计的是全局的信息,并不是指单个进程的数据.
1 | %iowait |
根据 iowait的定义可知, iowait是属于 idle的一个子类,为了便于理解,可以把 iowait 当成一种等待 IO 造成的 idle状态。
为什么CPU不会等待磁盘I/O呢?因为磁盘实在是太慢了,磁盘上的文件块,读入内核缓冲区的这个过程,是交给DMA去做的。cpu只是响应一下中断,就进入了被中断完成的唤醒状态。此时,如果有新的任务到来,这些cpu资源依然能够挪动身躯去做。
sar等命令,会读取/proc/stat中的数据,进行二次加工。由于sar本身也有一个刷新频率,所以它展现的是统计值。
原理
在内核中,user, sys, idle, iowait 四种状态,每个状态都有一个计数器,一个采样周期内统计每个状态的计数器,最后计算每个计数器占总计数的百分比,结果就是每个状态所占的百分比。
当发生时钟中断的时候,内核会检查 CPU 当前的状态,如果 CPU 正在执行内核空间的指令,则 sys 的计数器加 1 ,如果是用户空间的指令,则 user 的计数器加 1。
如果 CPU 此时处于 idle 状态,内核会做以下检查:
- 是否存在从该 CPU 发起的一个未完成的本地磁盘IO请求
- 是否存在从该 CPU 发起的网络磁盘挂载的操作
如果存在以上任一情况,则 iowait 的计数器加 1,如果都没有,则 idle 的计数器加 1。
iowait 常见的误解
- iowait 表示等待IO完成,在此期间 CPU 不能接受其他任务
从上面 iowait 的定义可以知道,iowait 表示 CPU 处于空闲状态并且有未完成的磁盘 IO 请求,也就是说,iowait 的首要条件就是 CPU 空闲,既然空闲就能接受任务,只是当前没有可运行的任务,才会处于空闲状态的,为什么没有可运行的任务呢? 有可能是正在等待一些事件,比如:磁盘IO、键盘输入或者等待网络的数据等 - iowait 高表示 IO 存在瓶颈
iowait 升高并不一定会导致等待IO进程的数量变多,也不一定会导致等待IO的时间变长,我们借助下面的图来理解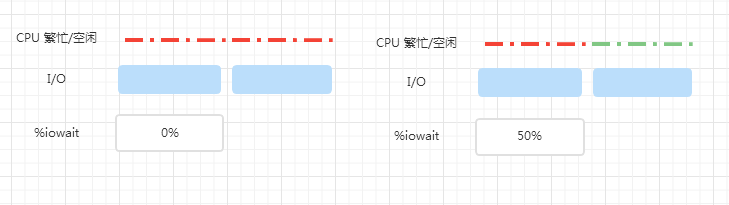
一个周期内,两个 IO 依次提交,左图的 CPU 一直处于繁忙状态,所以 %iowait 为 0%,右边的 CPU 繁忙时间只有左边的一半儿,另一半时间是空闲时间,因此 %iowait 为 50%,可以看到,IO 并没有变化,%iowait 确升高了,其实是因为 CPU 空闲时间增加了而已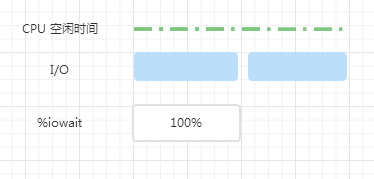
上图中,一个周期内,CPU 一直处于空闲状态,两个 IO 依次提交,整个周期内始终有 IO 再进行,所以 %iowait 为 100%
假如系统有能力同时处理多个 IO,现在两个 IO 同时提交
可以看到,系统处理两个并发 IO 只需要一半儿的时间,此时, %iowait 变成了 50%,其实,如果系统能同时处理 3 个并发 IO 的话,%iowait 依然为 50%
所以,%iowait 的高低与 IO 的多少没有必然的关系,而是与 IO 的并发度相关,仅根据 %iowait 的上升是不能确定 IO 负载增加的结论。
如何确定磁盘IO的瓶颈
当 %iowait 升高,还需要检查下 IO 量是否有明显增加以及avgrq-sz、avgqu-sz r_await、 w_await 等指标有没有增加,实际的操作以及应用有没有明显的变慢,如果都没有的话,应该没什么问题
1 | avgrq-sz: 向设备发出请求的平均大小(单位:扇区) |
有一套 ES 集群,在访问高峰时,有多个 ES 节点发生了严重的 STW 问题。有的节点竟停顿了足足有 7~8 秒。
解决方式也是比较容易的,把 ES 的日志文件,单独放在一块普通 HDD 磁盘上就可以了。所以在这种情况下,iowait不变,却能解决问题。
程序占用:/proc/%d/stat
包括:程序
1 | busy = atoll(vec[13].c_str()) + atoll(vec[14].c_str()) + atoll(vec[15].c_str()) + atoll(vec[16].c_str()); |
1 | utime=1587 该任务在用户态运行的时间,单位为jiffies |
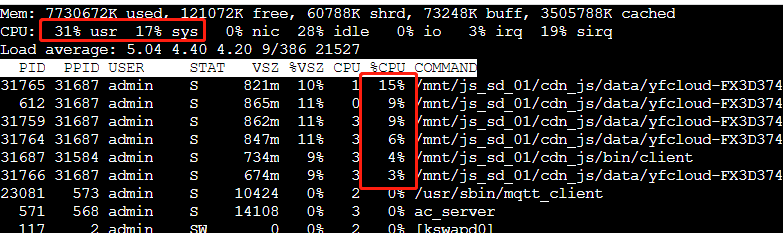
上图统计的cpu是总的cpu,最大值为100%,如果是4核,跑到25%就说明跑满一个核了。
otherCpu = cpu - io - myCpu;
send是到系统缓冲区,就返回了,这个拷贝到系统缓冲区使用的内核cpu是统计到myCpu的,但是系统底层发送tcp数据,这块消耗的cpu就是间接产生的了,可能会统计到otherCpu。
cpu问题问题分析:
- perf或者strace具体的函数,ltrace -bSp 19859查看库函数以及系统函数,strace查看系统函数
- top -H看是否有线程跑满100%,通过perf top -p查看系统调用,pstack或gdb查看堆栈,优先使用pstack pid
如果程序使用-pg,每隔10ms就会触发SIGPROF,如果父进程申请了大量内存,在fork时,就会导致fork执行时间相对较长,SIGPROF就会中断fork系统调用,导致fork返回ERESTARTNOINTR
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fcee4f989d0) = ? ERESTARTNOINTR (To be restarted)
gdb -p pid,handle SIGPROF stop
1 | static struct task_struct *copy_process(unsigned long clone_flags, |
内核在处理信号时,发现返回值为ERESTARTNOINTR,就会重新调用fork:
do_signal -> handle_signal:
static int
handle_signal(unsigned long sig, siginfo_t *info, struct k_sigaction *ka,
sigset_t *oldset, struct pt_regs *regs)
{
int ret;
/* Are we from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR;
break;
case -ERESTARTSYS:
if (!(ka->sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
}
...
注意到,对于ERESTARTNOINTR,内核会将ip减去2,由于int $0x80和sysenter都是2个字节,使得epi重新指向系统调用的指令。这样,当内核执行完信号处理函数后,又会重新执行被中断的系统调用。
然而,为了提高效率,现代操作系统通常使用“写时复制”(Copy-On-Write, COW)技术。这意味着在 fork 之后,父进程和子进程实际上共享相同的物理内存页,直到其中一个进程尝试修改某个内存页。只有在需要写入时,操作系统才会为该进程创建该内存页的副本。
创建一个绑定127.0.0.1和随机端口的监听socket A,再创建一个socket B,B与A建立一个https连接,使用包含AES128-GCM的加密套件,tcp sndbuf设置为524288,把B放到一个新线程中,不停地接收A发送的数据,A则发送30MB且3s后或不足30MB且3s后不再发送,收集A所在线程的cpu消耗值占系统cpu的比例K(以万分之一为单位)、A总共发送的字节数S以及发送这些数据消耗的时间T,cpuScore=K/(S/1MB/T)。比如S=9437184字节(发送了9MB的数据),T=3秒,K=2500(4核跑满了1核),那cpuScore=2500/(9437184/1048579/3)=2500/3=833,即1MB/s的https持续上传速度需要8.33%的cpu消耗