thrift协议
thrift编解码过程
Thrift是一种用于定义RPC服务和数据交换格式的框架,其中编解码过程是其重要的组成部分。下面简单介绍一下Thrift的编解码过程:
- 定义IDL接口:使用Thrift的IDL语言进行服务接口定义,包括服务方法、参数和返回值的类型及名称等信息。
- 生成代码:使用Thrift提供的代码生成器根据IDL文件生成各语言环境下可用的客户端和服务端代码。
- 编写客户端和服务端:使用生成的代码进行客户端和服务端的开发。
- 序列化请求:客户端将请求参数序列化为二进制格式,以便在网络上传输。
- 发送请求:客户端通过网络发送请求消息。
- 接收请求:服务端接收请求消息。
- 反序列化请求:服务端将接收到的二进制数据反序列化为具体的参数类型。
- 处理请求:服务端根据请求消息调用对应的服务方法,并返回处理结果。
- 序列化响应:服务端将返回结果序列化为二进制格式,以便在网络上传输。
- 发送响应:服务端通过网络发送响应消息。
- 接收响应:客户端接收响应消息。
- 反序列化响应:客户端将接收到的二进制数据反序列化为具体的返回值类型。
序列化过程
Thrift的序列化过程可以分为两个步骤:写入(Write)和读取(Read)。对于一个需要序列化的对象,Thrift会按照其定义的类型和顺序依次将其转换为二进制数据。
Thrift支持多种序列化协议,常用的有: Binary、Compact、JSON。binary序列化是一种二进制的序列化方式。不可读,但传输效率高。
下面是一个简单的例子,假设有一个Person对象:
1 | struct Person { |
其中,optional代表可不传该字段,如果需要传,则一定要调用Person的set方法,直接赋值age变量是不生效的!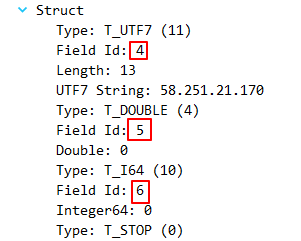
序列化过程如下:
- 写入字段标识符:对于每个字段,Thrift都要先写入一个字段标识符。在上述例子中,name字段的标识符为1,age字段的标识符为2(注意,age是optional类型,因此可能不存在)。标识符的信息可以用于解析和反序列化。
- 写入字段值:根据字段类型,将相应的值写入到二进制流中。例如,对于name字段,将其字符串值转换为UTF-8编码的字节数组后写入二进制流;对于age字段,将其整数值按照Varint编码写入二进制流。
- 重复以上步骤直到所有字段都被写入。
- 读取过程与写入过程类似,只不过是将二进制数据反序列化为具体的对象。对于每个字段,Thrift都要读取其标识符并根据标识符找到对应的类型和值。如果某个字段未出现在二进制数据中,说明该字段不存在,则使用默认值或抛出异常。
总的来说,Thrift的序列化过程是将对象按照定义的类型和顺序转换为二进制数据,并在读取时按照相同的方式进行反向转换。
Thrift请求响应模型
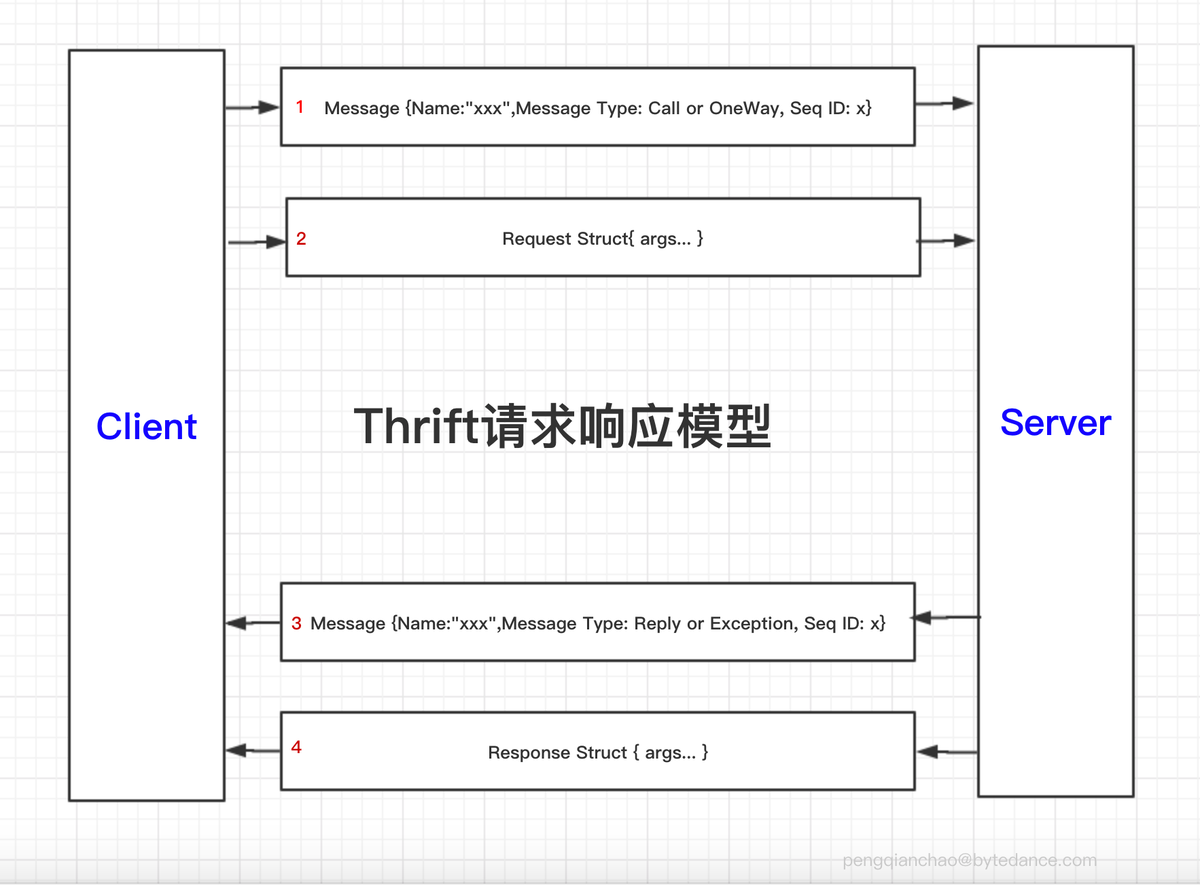
在Thrift的官方Doc中将Thrift的RPC请求响应描述为上面的四个步骤。图中,最外层只有Message和Struct。
这里可以将Message和Struct类比为TCP中的首部和负载。Message中放的是传递的元信息(metadata),Struct则包含的是具体传递的数据(payload)
注意这里不要理解成了Client,Server在一个TCP上Send了两次,而应该理解为字节流,2的数据紧跟在1的数据后面,4的数据紧跟在3的数据后面。
Message中主要包含Name,Message Type,Sequence ID等数据。
- Name:为调用的方法名
- Message Type:有Call, OneWay, Reply, Exception四种,在实际传递的时候,传递的是Type ID,这四种Type对应的Type ID如下 其中Call、OneWay用于Request, Reply、 Exception用于Response中。
1
2
3
4Call ---> 1
OneWay ---> 2
Reply ---> 3
Exception ---> 4
四者的含义如下:- Call: 调用远程方法,并且期待对方发送响应。
- OneWay: 调用远程方法,不期待响应。即没有步骤3,4。
- Reply: 表明处理完成,响应正常返回。
- Exception:表明出错。
- Sequence ID : 序列号, 有符号的四字节整数。在一个传输层的连接上所有未完成的请求必须有唯一的序列号,客户端使用序列号来处理响应的失序到达,实现请求和响应的匹配。服务端不需要检查该序列号,也不能对序列号有任何的逻辑依赖,只需要响应的时候将其原样返回即可。
在上面的Thrift请求响应模型中,有两种Struct:
- Request Struct
- Response Struct
这两种Struct的结构是一样的,都是由多个Field组成。
在有些实现中,会通过检查Thrift消息的第一个bit来判断使用了那种encoding:
1 —-> strict encoding
0 —-> old encoding
Message的Binary序列化下面的一张图就够了:
Struct装的是Thrift通信的实际参数,一个Struct由很多基本类型组合而成,要了解Struct怎么序列化的必须知道这些基本类型的序列化。
bool, byte, short, int, long, double采用的都是固定字节数编码。
长度前缀编码(4+N):string, byte array采用的是长度前缀编码,前四个字节(无符号四字节整数)表示长度,后面跟着的就是实际的内容。
map的编码(1+1+4+NX+NY):其中key-type和value-type可以是任何基本类型。注意将此处的map与python中的dict区分,这里的key和value各自都必须是同种类型,而python中dict是多态字典。
list和set的编码(1+4+N*X):注意与python中的list,set区分,这里的list,set中的元素必须是同一种类型。
field的编码(1+2+X):
field-type:1, field-id:2
filed不是一个实际存在的类型,而是一个抽象概念。field不独立出现,而是出现在struct内部,其中field-type可以是任何其他的类型,field-id就是定义IDL时该field在struct的编号,field-value是对应类型的值的序列化结果。
struct的编码,一个struct就是由多个field编码而成,最后一个field排列完成之后是一个stop field,这个field是一个8bit全为0的字节,它标志着一条Thrift消息的结束。
Compact序列化也是一种二进制的序列化,不同于Binary的点主要在于整数类型采用了zigzag 和 varint压缩编码实现。
早期, Thrift使用的是不基于帧的传输(unFramedTransport), 在这种情况下,处理器是直接向socket中读写数据。
之后, Thrift中引入了基于帧的传输(FramedTransport):Client/Server会首先在内存中缓存完整的请求/响应,当将request struct/response struct的最后一个字节缓存完成之后,会计算该消息的长度,然后向socket中写入该长度(4字节有符号整数),接着写入消息的实际内容。长度前缀+消息内容就组成了一个帧(Frame)。
1 | TSocketPtr socket(new TSocket(opt.path)); |