日常开发工具
在 CentOS 系统上安装 Google Chrome 浏览器,可以按照以下步骤进行:
添加 Google Chrome 的 YUM 源
在终端中输入以下命令:
sudo tee /etc/yum.repos.d/google-chrome.repo <<-‘EOF’
[google-chrome]
name=google-chrome - $basearch
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
enabled=1
gpgcheck=1
gpgkey=https://dl.google.com/linux/linux_signing_key.pub
EOF
安装 Google Chrome
输入以下命令进行安装:
yum -y install google-chrome-stable –nogpgcheck
启动 Google Chrome
在终端中输入以下命令启动 Google Chrome 浏览器:
google-chrome
这样就可以在 CentOS 系统上安装和使用 Google Chrome 浏览器了,输入法安装:https://www.google.cn/intl/zh-CN/inputtools/chrome/index.html。
Windows上的画图工具用来粘贴截图,分析问题,很到位,用来教学应该也是极好的。
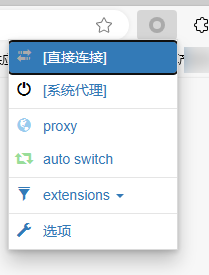
Edge浏览器可以下载Proxy SwitchyOmega插件,安装后走http代理,后续直接切换就好了。
VsCode:代码格式化c++时,令大括号不换行
“C_Cpp.clang_format_style”: “{ BasedOnStyle: Chromium, IndentWidth: 4, ColumnLimit: 150, }”,
ps -ef|grep f1mc2l|grep daemon=2| grep -v grep | awk ‘{print $2}’|xargs kill
Edge 安装沉浸式翻译插件
tar -czvf libs.tar.gz -C libs -H . 这样就不包含文件夹
gcc升级
1 | yum -y install centos-release-scl |
glibc升级
1 | $ ldd --version |
回退版本
1 | rpm -qa |grep glibc |
awk sed grep 三剑客awk、sed 和 grep 被称为 Unix/Linux 中的三剑客,是强大的文本处理工具。以下是每个工具的基本用法和一些常见示例:
grep - Global Regular Expression Print
grep 用于搜索文本中的匹配模式,通常用于过滤和查找特定内容。
基本用法
1 | grep [OPTIONS] PATTERN [FILE...] |
常用选项
-i:忽略大小写。-v:反转匹配,显示不包含模式的行。-r:递归搜索目录中的文件。-n:显示匹配的行号。-l:只显示匹配的文件名。
示例
1 | grep 'pattern' file.txt # 查找文件中包含 'pattern' 的行 |
sed - Stream Editor
sed 是一个流编辑器,用于文本替换、删除、插入和修改。
基本用法
1 | sed [OPTIONS] 'SCRIPT' [FILE...] |
常用选项
-n:抑制默认输出,通常与p命令配合使用。-i:直接修改文件而不是输出到标准输出。
常见脚本命令
s/old/new/:将old替换为new。d:删除匹配的行。p:打印匹配的行。
示例
1 | sed 's/old/new/g' file.txt # 将文件中所有 'old' 替换为 'new' |
awk - Aho, Weinberger, and Kernighan
awk 是一个强大的文本处理语言,用于模式匹配和数据操作。
基本用法
1 | awk 'PATTERN {ACTION}' [FILE...] |
常用功能
$0:整行。$1, $2, ...:第 1、2、… 列。FS:字段分隔符(默认为空格或制表符)。NR:当前行号。NF:当前行字段数。
示例
1 | awk '{print $1}' file.txt # 打印文件的第一列 |
综合示例
假设有一个名为 data.txt 的文件,其内容如下:
1 | Alice 30 |
使用 grep
1 | grep 'Alice' data.txt # 查找包含 'Alice' 的行 |
使用 sed
1 | sed 's/Alice/Alicia/' data.txt # 将 'Alice' 替换为 'Alicia' |
使用 awk
1 | awk '{print $1}' data.txt # 打印第一列(名字) |
通过掌握这些基本用法和示例,你可以在文本处理和数据分析中高效地利用 grep、sed 和 awk。
su: 直接切换到另一个用户,需要输入目标用户的密码。su - 切换并加载环境变量。
sudo -i: 提升到 root 权限并模拟一个登录会话,加载 root 用户的环境变量,需要输入当前用户的密码。
sudo su: 提升到 root 权限并切换到 root 用户,不加载 root 的环境变量,需要输入当前用户的密码。sudo su - 切换并加载环境变量。