http2知识点
http1.x的缺点
安全不足和性能不高。
HTTP/2 借用了哈夫曼编码对于Header进行高效压缩,提高传输效率。
HTTP1.X中最大的问题是队头阻塞,HTTP1.X中浏览器对于同一域名的并发连接访问此时是有限的,所以常常会导致只有个位数的连接可以正常工作,后续的连接都会被阻塞。
HTTP1.1支持请求管道化(pipelining)。基于HTTP1.1的长连接,使得请求管线化成为可能。管线化使得请求能够“并行”传输。
注意:这里的“并行”并不是真正意义上的并行传输,需要注意的是,服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
也就是说,HTTP管道化可以让我们把先进先出队列从客户端(请求队列)迁移到服务端(响应队列)。
HTTP/2 解决队头阻塞是以 HTTP1.X 管道化的为基础拓展,它使用了二进制流和帧概念解决应用层队头阻塞。应用层的阻塞被解决便是实现流并发传输。
为了控制资源的资源的获取顺序,HTTP在并发传输的基础上实现请求优先级以及流量控制,流的流量控制是考虑接收方是否具备接收能力。
二进制帧
二进制帧保留Header+Body传输结构,但是打散了内部的传输格式,把内容拆分为二进制帧的格式,HTTP/2把报文的基本传输单位叫做帧,而帧分为两个大类 HEADERS(首部) 和 DATA(消息负载),一个消息划分为两类帧传输同时采用二进制编码。
这种做法类似Chunked化整数据的方式,把Header+body等同的帧数据,同时内部通过类型判断进行标记。
HTTP/2定义了多大10种类型帧,主要分为数据帧和控制帧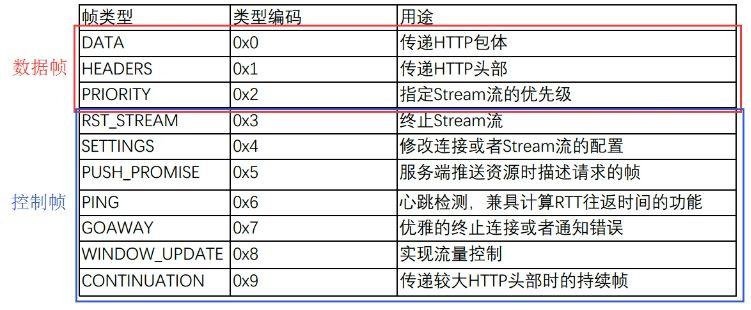
帧类型后面接着标志位,标志位用于携带一些控制信息,比如下面:
- END_HEADERS:表示头数据结束标志,相当于 HTTP1.X 里头后的空行“\r\n”。
- END_Stream:表示单方向数据发送结束,后续不会再有数据帧。
- PRIORITY:表示流的优先级。
流与多路复用
核心概念:
- 流是二进制帧的双向传输序列。
- 一个 HTTP/2 的流就等同于一个 HTTP/1 里的“请求 - 应答”。
HTTPP2的流特点 - 一个TCP复用多个“请求响应”,支持并发传输
- 流和流之间独立,但是内部通过StreamId保证顺序。
- 流可以设置优先级,让服务器优先处理特定资源,比如先传 HTML/CSS,后传图片,优化用户体验
- 流 ID 不能重用,只能顺序递增,客户端发起的 Stream ID 是奇数,服务器端发起的 Stream ID 是偶数。流标识符不是无限的,如果ID递增到耗尽,此时可以发送控制帧“GOAWAY”,真正关闭 TCP 连接。客户端在一个连接最多发出2^30请求,大约为10亿个。
- 第 0 号流比较特殊,它不能关闭,也不能发送数据帧,只能发送控制帧,用于流量控制。
- 在流上发送“RST_STREAM”帧可以随时终止流,取消流的接收或发送
HTTP/2 在一个连接上使用多个流收发数据本身默认就会是长连接,所以永远不需要“Connection”头字段(keepalive 或 close)。
RST_STREAM帧的常见应用是大文件中断重传,在 HTTP/1 里只能断开 TCP 连接重新“三次握手”进行请求重连,这样处理的成本很高,而在 HTTP/2 里就可以简单地发送一个“RST_STREAM”中断流即可进行暂停,此时长连接会继续保持。
当连接没有开始的时候,所有流都是空闲状态,此时的状态可以理解为“不存在待分配”。客户端发送 HEADERS帧之后,流就会进入”open”状态,此时双端都可以收发数据,发送数据之后客户端发送一个带“END_STREAM”标志位的帧,流就进入了“半关闭”状态。响应数据也需要发送 END_STREAM 帧,表示自己已经接收完所有数据,此时也进入到“半关闭”状态。如果请求流ID耗尽,此时就可以发送一个 GOAWAY 完全断开TCP连接,重新建立TCP握手。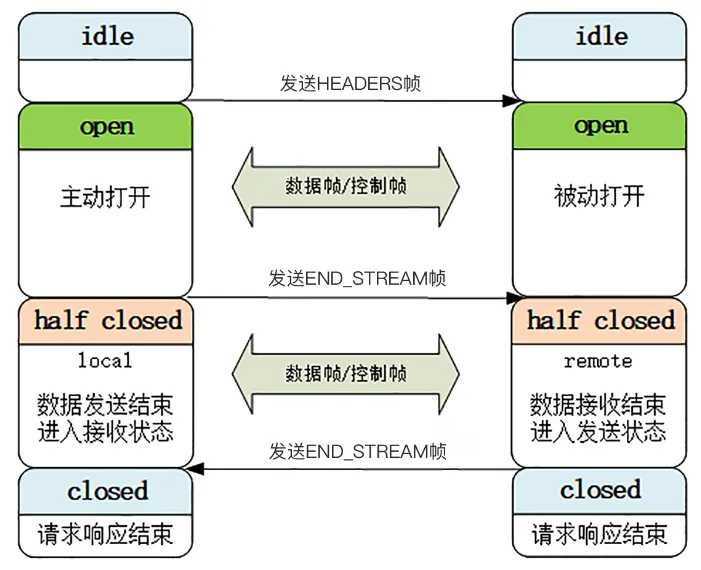
应用层队头阻塞解决
HTTP2 解决了应用层的的队头阻塞,但没有解决TCP队头阻塞问题,我们可以认为HTTP2的队头阻塞很像是把管道化的概念实现的更好。
HTTP1.X时,各大服务网站的解决方式是使用资源分割的方式,配合多域名和主机进行多个IP避开浏览器单个域名的限制,同时结合CDN加速请求。但是这样做需要分片多个TCP请求,TCP的连接请求的资源消耗比较大。
在不稳定的网络传输中很有可能出现TCP数据传输阻塞问题,假设A网站要给B用户一个CSS文件,HTTP知道他要被拆分为三个独立资源的包,按照ID连起来拼成完整的数据。此时如果数据包1和3都传输过去了,但是2在传输过程突然出现丢包,此时接收方组装的时候发现ID不连续,这时候是不能够把1后面的数据包3传出去的,TCP的处理方式是 将数据包3保存在其接收缓冲区(receive buffer)中,直到它接收到数据包2的重传副本然后重新拼出完整的文件,然后才能给浏览器(这至少需要往返服务器一次)。
在HTTP1.X中如果出现上面TCP队头阻塞情况,可以通过直接丢弃原有的TCP开新的TCP连接解决问题,虽然开销很大但是至少可以确保传输在正常进行。
而HTTP2在这种情况下就开倒车了,因为HTTP2的理念是一个TCP连接,所以只能通过等待TCP连接重传来解决丢包的问题,这种情况下整个TCP连接都要阻塞,如果是大文件传输,这种体验会更加糟糕。
TCP 协议本身的缺陷加上HTTP2一个TCP连接设计,HTTP2的TCP层队头阻塞问题十分显著。HTTP1.X在解决TCP队头阻塞虽然笨,但是实际体验要比HTTP2好得多。
以上这就是TCP的队头阻塞问题。顺带提一句HTTP3 通过了QUIC协议替换掉TCP协议,彻底实现了无队头阻塞的HTTP连接。
Header压缩
HTTP/2 头部压缩是基于HPACK算法实现的,主要通过三个技术点实现:
- 静态表 :内部预定义了61个Header的K/V 数值
- 动态表 :利用动态表存储不在静态表的字段,从62开始进行索引,主要存储一些动态变化的请求头部。
- 哈夫曼(霍夫曼、赫夫曼)编码:一种高效数据压缩的数据结构,被广泛应用在计算机的各个领域。
静态表
静态表包含了一下基本不会出现变化的字段,静态表设计固定61个字段,这些字段都是请求中高频出现的字段,比如请求方法,资源路径,请求状态等等。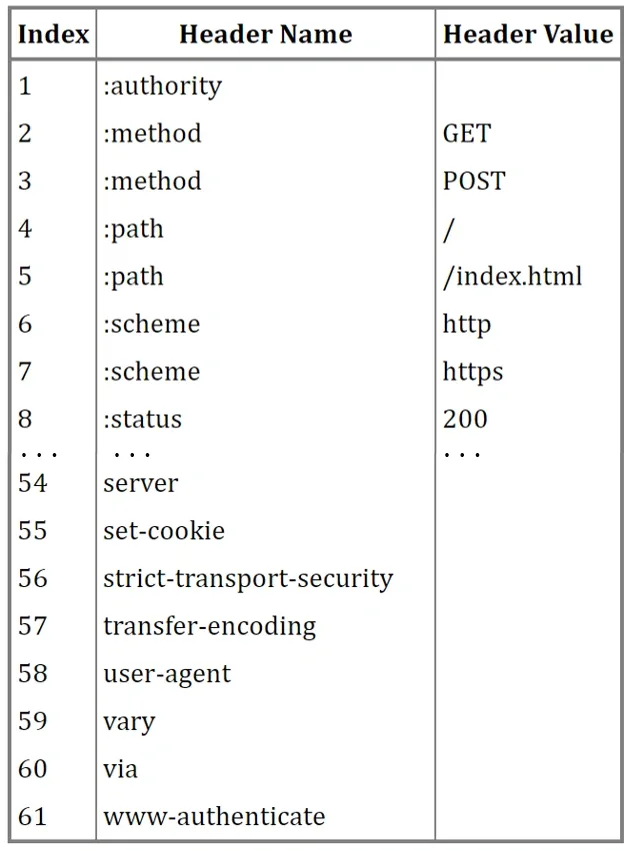
RFC中规定,如果头部字段属于静态表范围并且 如果Value 是变化的,那么它的 HTTP/2 头部前 2 位固定为 01。
通过抓包了解server在HTTP的格式: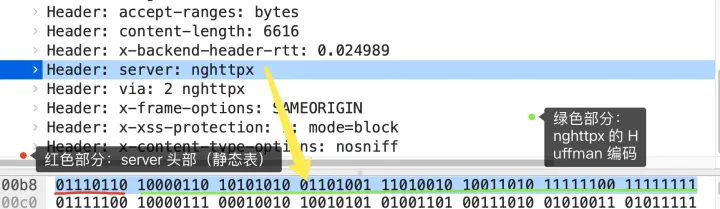
1 | server: nghttpx\r\n |
算上冒号空格和末尾的\r\n,共占用了 17 字节,而使用了静态表和 Huffman 编码,可以将它压缩成 8 字节,压缩率大概 47 %。
上面的 server的值是如何定义的,首先通过index找到 server字段的序列号为54,二进制为110110,同时它的Value是变化的,所以是01开头,最后组成01110110。
接着是Value部分,根据上文RFC哈夫曼编码的规则,首个比特位是用来标记是否哈夫曼编码的,所以跳过字节首位,后面的7位才是真正用于标识Value的长度,10000110,它的首位比特位为 1 就代表 Value 字符串是经过 Huffman 编码的,经过 Huffman 编码的 Value 长度为 6。
整个进化结果就是,字符串 nghttpx 转为二进制之后,然后经过 Huffman 编码后压缩成了 6 个字节。 哈夫曼的核心思想就是把高频出现的“单词”用尽可能最短的编码进行存储,比如 nghttpx 对应的哈夫曼编码表如下: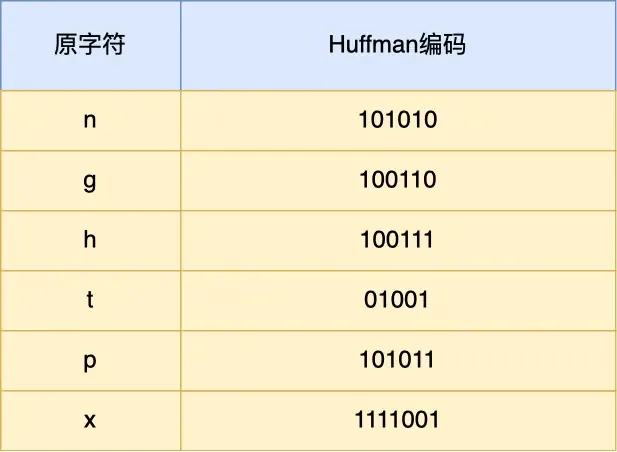
一共是六个字节的数据,从二进制通过查表的结果如下:
server 头部的二进制数据对应的静态头部格式如下: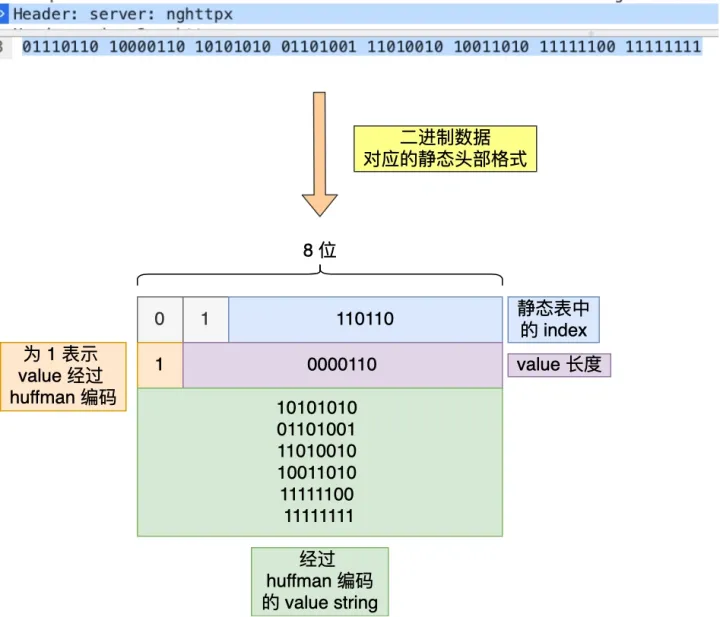
动态表
静态表包含了固定字段但是值不一定固定的表,而动态表则用存储静态表中不存在的字段,动态表从索引号62开始,编码的时候会随时进行更新。
比如第一次发送user-agent字段,值经过哈夫曼编码之后传输给接收方,双方共同存储值到各自的动态表上,下一次如果需要同样的user-agent字段只需要发送序列号index即可,因为双方都把值存储在各自对应的index索引当中。
请求优先级
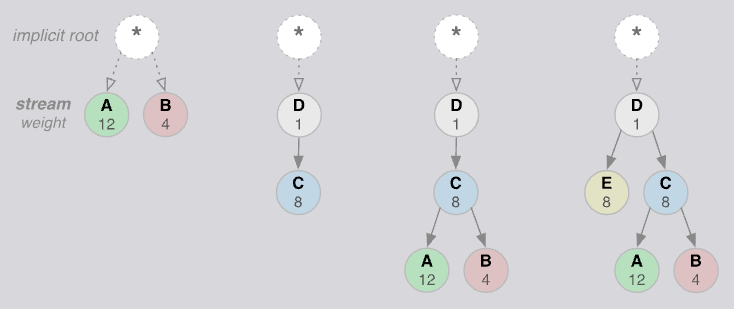
为此HTTP2设计允许每个流都可以配置单独的权重和依赖关系:
- 可以为每个流分配一个介于 1 和 256 之间的整数权重。
- 可以为每个流提供对另一个流的显式依赖关系。
WINDOW_UPDATE 帧
- 发送端每发送一个DATA帧,就把window流量窗口的值递减,递减量为这个帧的大小,如果流量窗口大小小于DATA帧,则必须对于流进行拆分,直到小于windows流量窗口为止,而流量窗口递减到0的时候,不能发送任何帧。
- 接收端通过 WINDOW_UPDATE 帧,告知发送方自己的负载能力。
SETTING 帧
- SETTINGS_HEADER_TABLE_SIZE:HPACK(header压缩算法) header表的最大长度,默认值 4096
- SETTINGS_ENABLE_PUSH:客户端发向服务端的配置,若设置为 true,客户端将允许服务端推送响应,默认值 true
- SETTINGS_MAX_CONCURRENT_STREAMS:同时打开的 stream 最大数量,通常意味着同一时刻能够同时响应的请求数量,默认无限
- SETTINGS_INITIAL_WINDOW_SIZE:流控的初始窗口大小,默认值 65535
- SETTINGS_MAX_FRAME_SIZE:对端能够接收帧的最大长度,默认值16384
- SETTINGS_MAX_HEADER_LIST_SIZE:对端能够接收的 header 列表最大长度,默认不限制
其余知识点
为了便于识别和传输,可以将字符串通过base64编码。
Base64编码是一种将二进制数据转换为文本字符的编码方式,通常用于在文本环境中传输二进制数据。Base64编码使用64个可打印字符来表示二进制数据,它的基本原理如下:
- 字符集: Base64编码使用64个字符,通常包括大写字母 A-Z(26个字符)、小写字母 a-z(26个字符)、数字 0-9(10个字符),以及两个额外的字符 ‘+’ 和 ‘/‘。有时,为了适应不同的场景,字符集中的 ‘+’ 和 ‘/‘ 可能会被替换成其他字符。
- 分组: Base64将原始数据按照3字节(24位)为一组进行分割。如果最后一组的字节数不足3字节,会进行填充。
- 二进制到字符的映射: 将每组的3字节数据划分为四个6位的块,然后将这些6位块映射到Base64字符集上。这样,每组3字节的数据就会被映射为4个Base64字符。
- 填充: 如果原始数据长度不是3字节的倍数,Base64编码会使用一个或两个 ‘=’ 字符进行填充,确保编码后的长度是4的倍数。
- URL安全的Base64: 在URL参数中使用Base64时,通常会采用一些变种,例如将 ‘+’ 替换为 ‘-‘,将 ‘/‘ 替换为 ‘_’,以避免与URL中的特殊字符冲突。