网络篇
网络通信模型

TCP/IP与OSI最大的不同在于:OSI是一个理论上的网络通信模型,而TCP/IP则是实际运行的网络协议。
为什么连接的时候是三次握手,关闭的时候却是四次挥手?
三次握手
第一次握手:第一次握手是客户端发送同步报文到服务端,这个时候客户端是知道自己具备发送数据的能力的,但是不知道服务端是否有接收和发送数据的能力;
第二次握手:当服务端接收到同步报文后,回复确认同步报文,此时服务端是知道客户端具有发送报文的能力,并且知道自己具有接收和发送数据的能力,但是并不知道客户端是否有接收数据的能力;
第三次握手:当客户端收到服务端的确认报文后,知道服务端具备接收和发送数据的能力,但是此时服务端并不知道自己具有接收的能力,所以还需要发送一个确认报文,告知服务端自己是具有接收能力的。
当整个三次握手结束过后,客户端和服务端都知道自己和对方具备发送和接收数据的能力,随后整个连接建立就完成了,可以进行后续数据的传输了。
三次握手是为了建立可靠的数据传输通道,四次挥手则是为了保证等数据完全的被接收完再关闭连接。既然提到需要保证数据完整的传输完,那就需要保证双方都达到关闭连接的条件才能断开。
四次挥手

第一次挥手客户端发起关闭连接的请求给服务端;
第二次挥手:服务端收到关闭请求的时候可能这个时候数据还没发送完,所以服务端会先回复一个确认报文,表示自己知道客户端想要关闭连接了,但是因为数据还没传输完,所以还需要等待;
第三次挥手:当数据传输完了,服务端会主动发送一个 FIN 报文,告诉客户端,表示数据已经发送完了,服务端这边准备关闭连接了。
第四次挥手:当客户端收到服务端的 FIN 报文过后,会回复一个 ACK 报文,告诉服务端自己知道了,再等待一会就关闭连接。
先说结论,关闭过程主要有两种情况:
- 如果接收缓冲区还有数据未读,会先把接收缓冲区的数据清空,然后给对端发一个RST。
- 如果接收缓冲区是空的,那么就调用 tcp_send_fin() 开始进行四次挥手过程的第一次挥手。
1 | void tcp_close(struct sock *sk, long timeout) |
如果发送缓冲区有数据时,执行close了,会怎么样?
以前以为,这种情况下,内核会把发送缓冲区数据清空,然后四次挥手。
1 | void tcp_send_fin(struct sock *sk) |
此时,还有些数据没发出去,内核会把发送缓冲区最后一个数据块拿出来。然后置为 FIN。
socket 缓冲区是个先进先出的队列,这种情况是指内核会等待TCP层安静把发送缓冲区数据都发完,最后再执行 四次挥手的第一次挥手(FIN包)。
有一点需要注意的是,只有在接收缓冲区为空的前提下,我们才有可能走到 tcp_send_fin() 。而只有在进入了这个方法之后,我们才有可能考虑发送缓冲区是否为空的场景。
UDP不用发送缓冲区?
事实上,UDP不仅有发送缓冲区,也用发送缓冲区。
一般正常情况下,会把数据直接拷到发送缓冲区后直接发送。
还有一种情况,是在发送数据的时候,设置一个 MSG_MORE 的标记。
1 | ssize_t send(int sock, const void *buf, size_t len, int flags); // flag 置为 MSG_MORE |
大概的意思是告诉内核,待会还有其他更多消息要一起发,先别着急发出去。此时内核就会把这份数据先用发送缓冲区缓存起来,待会应用层说ok了,再一起发。
1 | int udp_sendmsg() |
因此,不管是不是 MSG_MORE, IP都会先把数据放到发送队列中,然后根据实际情况再考虑是不是立刻发送。
而我们大部分情况下,都不会用 MSG_MORE,也就是来一个数据包就直接发一个数据包。从这个行为上来说,虽然UDP用上了发送缓冲区,但实际上并没有起到”缓冲”的作用。
udp可以通过使用 connect 函数建立连接,可以将套接字与指定的目标地址和端口号绑定在一起,这样在调用 send 或 sendto 函数发送数据报时,就不需要再指定目标地址和端口号,而是直接将数据发送到预先连接的目标地址和端口号。这样可以简化数据发送的操作,并且可以提高性能。
问题点
- 为什么握手要三次,挥手却要四次呢?
那是因为握手的时候并没有数据传输,所以服务端的 SYN 和 ACK 报文可以一起发送,但是挥手的时候有数据在传输,所以 ACK 和 FIN 报文不能同时发送,需要分两步,所以会比握手多一步。 - 为什么客户端在第四次挥手后还会等待 2MSL?
等待 2MSL 是因为保证服务端接收到了 ACK 报文,因为网络是复杂了,很有可能 ACK 报文丢失了,如果服务端没接收到 ACK 报文的话,会重新发送 FIN 报文,只有当客户端等待了 2MSL 都没有收到重发的 FIN 报文时就表示服务端是正常收到了 ACK 报文,那么这个时候客户端就可以关闭了。 - 其中CLOSEWAIT是出现在被动断开方,如上图就是服务端。如果服务端出现大量的CLOSE_WAIT状态,一般情况下是由于程序中没有正常调用close()关闭连接,所以出现这个问题一般是会结合开发一起找原因。
- FINWAIT2状态会等待服务端发送SYN断开连接,如果服务端一直没有发送断开,客户端会等待tcp_fin_timeout时间断开socket连接,如果有大量的FINWAIT2状态,就要检查服务端的应用程序是否调用close()关闭连接,如果一时查不出原因,可以修改内核参数tcp_fin_timeout的时间,比如:net.ipv4.tcp_fin_timeout=30。
- TIMEWAIT状态有一个默认过期时间,默认是2MSL(最大生存时间),不同的操作系统默认的MSL是不一样的。如果有大量的TIMEWAIT,就会造成本地端口不释放,无法通过这个端口建立新的连接,如果本地端口都用完了,就会出现无法建立TCP连接来访问服务端了。
解决方法一般有两种(具体需要根据自身情况来定):- 调节内核参数
以CentOS为例,主要的参数有tcp_max_tw_buckets、tcp_tw_recycle、tcp_tw_reuse这三个配置项。
(1)、tcp_max_tw_buckets:该配置项用来防范简单的DoS攻击 ,在某些情况下,可以适当调大,但绝对不应调小。
(2)、tcp_tw_recycle:该配置项可用于快速回收处于TIMEWAIT状态的socket以便重新分配。默认是关闭的,必要时可以开启该配置。
(3)、tcptwreuse:开启该选项后,kernel会复用处于TIMEWAIT状态的socket,当然复用的前提是“从协议角度来看,复用是安全的”。 - 修改应用程序
(1)、将TCP短连接改造为长连接。通常情况下,如果发起连接的目标也是自己可控制的服务器时,它们自己的TCP通信最好采用长连接,避免大量TCP短连接每次建立/释放产生的各种开销;如果建立连接的目标是不受自己控制的机器时,能否使用长连接就需要考虑对方机器是否支持长连接方式了,可以等客户端发起的连接没有Connection: Close时将连接保存下来下次服用。
(2)、通过getsockopt/setsockoptapi设置socket的SO_LINGER选项。
- 调节内核参数
- SO_LINGER其取值和处理如下:
1、设置 l_onoff为0,则该选项关闭,l_linger的值被忽略,等于内核缺省情况,close调用会立即返回给调用者,如果可能将会传输任何未发送的数据;
2、设置 l_onoff为非0,l_linger为0,则套接口关闭时TCP夭折连接,TCP将丢弃保留在套接口发送缓冲区中的任何数据并发送一个RST给对方,
而不是通常的四分组终止序列,这避免了TIME_WAIT状态;
3、设置 l_onoff 为非0,l_linger为非0,当套接口关闭时内核将拖延一段时间(由l_linger决定)。
如果套接口缓冲区中仍残留数据,进程将处于睡眠状态,直到(a)所有数据发送完且被对方确认,之后进行正常的终止序列(描述字访问计数为0)
或(b)延迟时间到。此种情况下,应用程序检查close的返回值是非常重要的,如果在数据发送完并被确认前时间到,close将返回EWOULDBLOCK错误且套接口发送缓冲区中的任何数据都丢失。close的成功返回仅告诉我们发送的数据(和FIN)已由对方TCP确认,它并不能告诉我们对方应用进程是否已读了数据。如果套接口设为非阻塞的,它将不等待close完成。
第一种情况其实和不设置没有区别,第二种情况可以用于避免TIME_WAIT状态,但在Linux上测试的时候,并未发现发送了RST选项,而是正常进行了四步关闭流程,初步推断是“只有在丢弃数据的时候才发送RST”,如果没有丢弃数据,则走正常的关闭流程。第三种情况其实就是第一种和第二种的折中处理,且当socket为非阻塞的场景下是没有作用的。对于应对短连接导致的大量TIME_WAIT连接问题,个人认为第二种处理是最优的选择,libmemcached就是采用这种方式,从实测情况来看,打开这个选项后,TIME_WAIT连接数为0,且不受网络组网(例如是否虚拟机等)的影响。
TCP流量控制和拥塞控制
流量控制和拥塞控制是两个不同的控制机制,它们都可以在TCP连接中提高连接的质量和性能。流量控制主要用于控制数据发送方发送数据的速率,以保证接收方正常处理和处理数据流的巨大负载。拥塞控制则是用于保护网络免于超负载和网络拥塞的出现。
TCP流量控制
TCP流量控制通过使用滑动窗口协议来控制数据的传输,以避免接收方不能够处理太多的数据而导致数据的丢失。它使用在发送方和接收方之间的缓存区来控制连接。每个连接都可以通过窗口大小来决定能够发送的数据量。
接收方可以通过发送窗口大小来限制发送方发送的数据量。如果接收方的窗口大小为0,则发送方必须等待接收方改变窗口大小,才能继续发送数据。
流量控制就像现实生活中物流领域中A和B两个仓库,A往B运送货物时只关心仓库B的剩余空间来调整自己的发货量,而不关心高速是否拥堵。
TCP拥塞控制
TCP拥塞控制通过动态调整拥塞窗口的大小来避免网络拥塞。当网络保持拥塞状态时,发送端会减小拥塞窗口的大小以降低流量。
看到一篇文章说到TCP 传输层拥塞控制算法并不是简单的计算机网络的概念,也属于控制论范畴,感觉这个观点很道理。
拥塞窗口的大小是根据RTT(往返时间)和网络状况动态调整的。TCP发送端在检测到拥塞后将减小拥塞窗口,而在网络得到改善后,它将增加拥塞窗口大小。
拥塞窗口属于 TCP 连接中发送方的一部分。拥塞窗口的大小是控制数据发送速度的关键参数,它告诉发送方它可以在未达到确认之前发送多少数据段。拥塞窗口的大小由 TCP 发送方动态计算、调整,并且受到 TCP 流量控制和拥塞控制的影响。

Slow Start
当 TCP 连接开始时,拥塞窗口大小被设置为一个段的大小,这是 MSS 和最大 TCP 头部可以占据的空间之和。Slow Start 算法使拥塞窗口按指数增长,直到发送方发现网络出现瓶颈为止。在每个 RTT (往返时间) 时间段后,拥塞窗口的大小就会翻倍,直到达到一个预设的慢开始门限 (Slow Start Threshold ,SST)。当拥塞窗口大小达到慢开始门限值时,TCP 就进入另一种拥塞控制状态。
Congestion Avoidance
TCP 的拥塞控制状态从单调的慢开始阶段移动到了稳定的拥塞避免状态。在该阶段中,TCP 拥塞窗口增长速度较慢,成线性增长。一旦 TCP 连接检测到网络出现拥塞,它就通过将阈值 (SST) 设置为当前窗口大小的一半,并将拥塞窗口大小设置为参数 MSS 来降低它的速度,即退回到慢开始状态,重新开始拥塞控制的过程。
举个例子,假设 TCP 进入拥塞避免阶段时拥塞窗口大小为 4 ,因此第一轮往返可以发出 4 个报文段。假设这 4 个段均成功送达并收到 ACK 确认,每个 ACK 确认为拥塞窗口增加 个报文段,4 个 ACK 刚好增加 1 个报文段。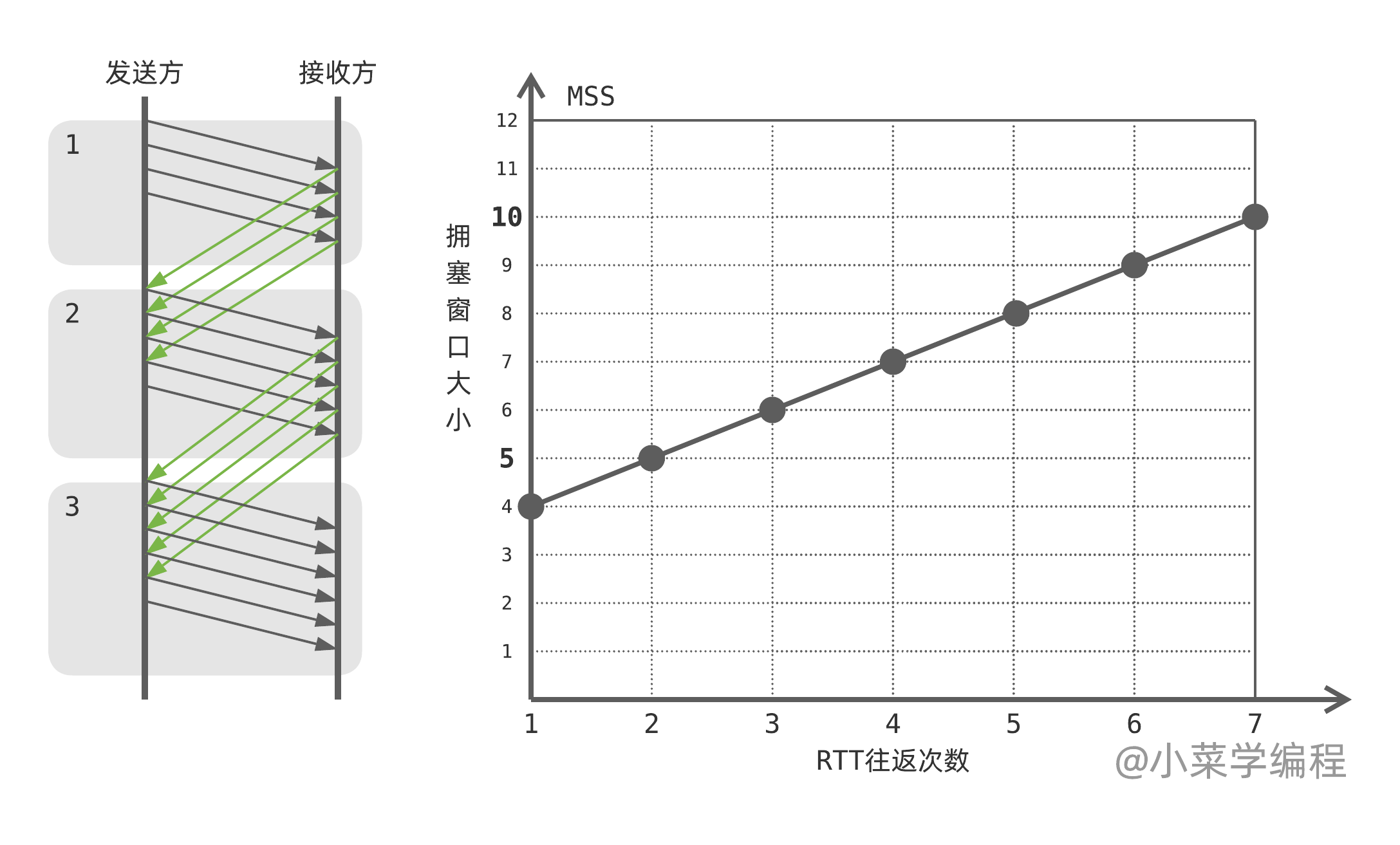
Fast Retransmission
当 TCP 发送数据时,如果接收方没有确认收到数据,则发送方会重新发送该数据。Fast Retransmission 算法是在收到重复 ACK 包时启动的,当 TCP 接收到三个重复 ACK 时,就假定该段丢失,从而进行快速重传操作。这使得 TCP 能够更快地重传丢失的分组,而不必等待超时。
很显然,快速重传算法会受到捎带确认机制的制约。试想接收方刚好没有数据要发,因此 ACK 确认被延迟,乃至合并,发送方就不会检测到重复确认。
为了解决这个矛盾,TCP 规定接收方接到乱序数据后就立马发送 ACK 确认。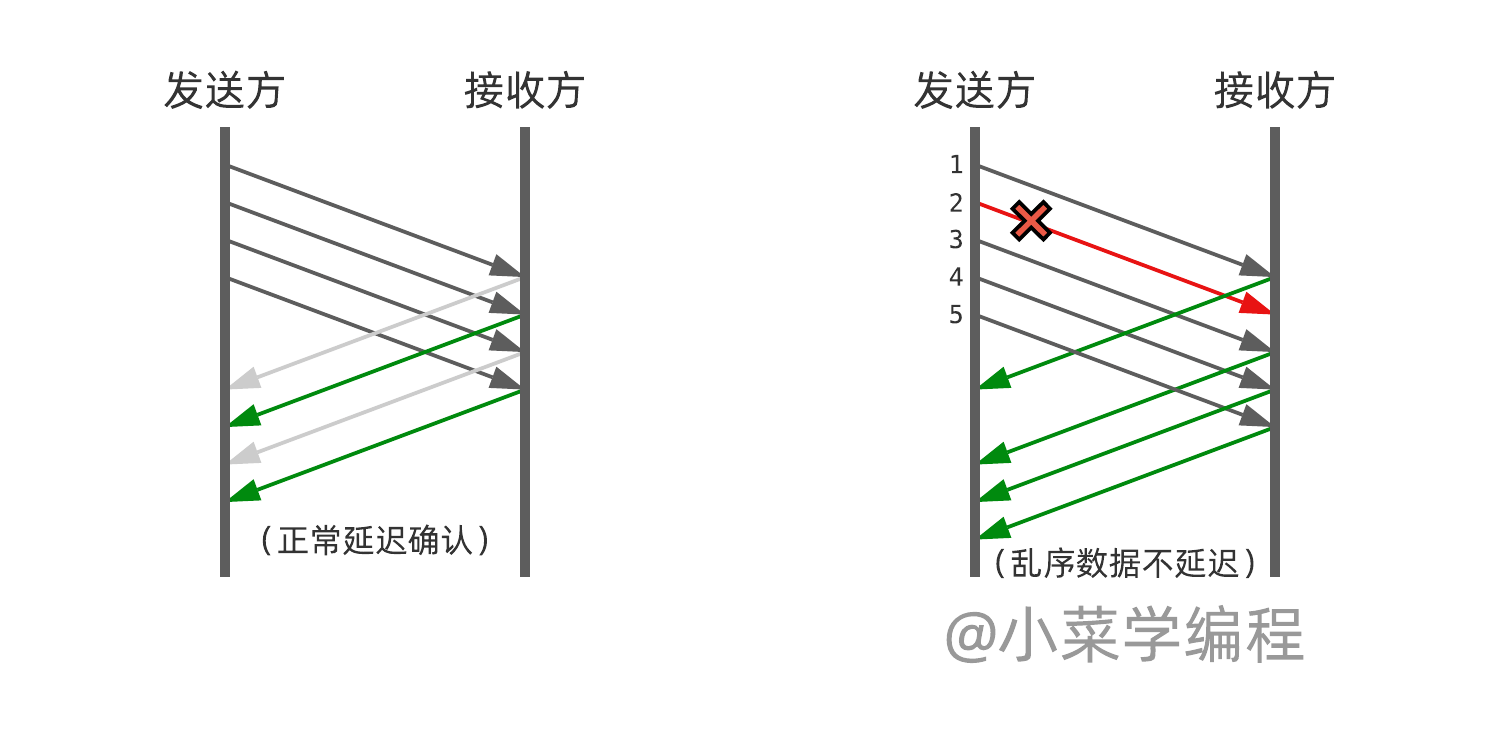
Fast Recovery
Fast Recovery 用于解决Fast Retransmission 可能引发的问题。它表示在收到三个重复 ACK 包时,TCP 的拥塞窗口大小被减半,同时进入快速恢复状态。由于发送方现在认为网络很可能没有发生拥塞(如果网络发生了严重拥塞,就不会一连有好几个报文段连续到达接收方,也就不会导致接收方连续发送重复确认)。因此与慢开始不同之处就是现在不执行慢开始算法(即拥塞窗口现在不设置为1)而是把拥塞窗口的值设置为慢开始门限减半后的值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
注意:有的快重传实现是把开始时的拥塞窗口cwnd值再增大一些(增大3个报文段),即等于ssthresh + 3*MSS 这样做的理由是:既然发送方收到三个重复的确认,就表明有三个分组已经离开了网络。这三个分组不再消耗网络资源而是停留在接收方的缓存中。可见现在网络中并不是堆积了分组而是减少了三个分组。因此可以适当把拥塞窗口扩大些。
当采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络超时时才使用。
实际上接收方的缓存空间总是有限的,接收方根据自己的接收能力设定了接收窗口rwnd,并把这个窗口值写入TCP首部中的窗口字段,传送给发送方。因此,从接收方对发送方的流量控制的角度考虑,发送方的发送窗口一定不能超过对方给出的接收窗口值rwnd.那么,发送方的窗口的上限值应当取为接收方窗口rwnd和拥塞窗口cwnd这两个变量中较小的一个。
通过读取 /proc/net/snmp 文件,可以了解系统当前的网络流量、连接数、重传率等信息,这些信息对于网络调优、性能优化、故障排查等非常有用。
理解 listen 的第二个参数
Linux内核协议栈为一个tcp连接管理使用两个队列,分别是:
半连接队列:用来保存SYN_SENT和SYN_RECV两个状态的连接。也就是三次握手还没有完成,连接还没建立的连接。
全连接队列:用来保存保存ESTABLISHED状态的连接。三次握手已经完成的连接。
全连接队列存放三次握手成功的连接。如果当服务器不调用accept函数,没有将全连接队列的请求拿出来,当该队列满的时候,客户端的连接就无法再过来,而是存放在半连接队列中,所以当全连接满时,服务器会处于SYN_RECV状态。
在linux 2.2以后,listen的第二个参数,指的是在完成TCP三次握手后的队列。即在系统accept之前的队列。已经完成的队列。The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog.
举个例子:全连接队列就像餐馆里的座位数目,处于全连接队列里的连接就像是正在用餐的客人,而一旦被accept,就相当于用餐结束,客人离开餐馆,座位数目+1。半连接队列像是在餐馆外面等待的人,当餐馆有座位时(全连接队列没满)就让排队的人进入餐馆坐着(把半连接队列里的连接放进全连接,当然他们的三次握手也随之完成,状态进入ESTABLISHED),座位数-1。
之所以要这样设计,是为了尽可能多地服务更多的客人,如果不设置半连接队列,座位满了,客人就直接走了,如果客人刚走就有空座位了,岂不是得不偿失?所以TCP为了尽可能多得利用资源,设计了半连接和全连接队列。当然排队的队列也不能太长,因为与其增加排队的长度,不如多加几张桌子(多创建几个进程/线程进行accept)。
使用SYN Cookies机制,服务器在接收到客户端的TCP SYN请求后,会生成一个加密的cookie值,并将该cookie值作为SYN-ACK包的一个选项返回给客户端。当客户端再次发送请求并携带该cookie值,服务器在收到这个SYN请求时,会根据这个cookie值重建之前已建立好的连接,而不是将此请求加入到半开连接(half-open connections)队列中等待正常的三次握手完成后再建立连接。因为该cookie值的长度较短,通常仅占用TCP头的几个字节,因此可以提高服务器的抗攻击能力,避免因短时间内处理大量半开连接而导致的资源耗尽和崩溃。
1 | $ cat /proc/sys/net/ipv4/tcp_syncookies |
为什么TCP握手需要三次,两次行不行?
不行。TCP进行可靠传输的关键就在于维护一个序列号,三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值。
如果只是两次握手, 至多只有客户端的起始序列号能被确认, 服务器端的序列号则得不到确认。
Get与Post区别
Get:指定资源请求数据,刷新无害,Get请求的数据会附加到URL中,传输数据的大小受到url的限制。
Post:向指定资源提交要被处理的数据。刷新会使数据会被重复提交。post在发送数据前会先将请求头发送给服务器进行确认,然后才真正发送数据。
为什么TCP挥手需要4次
主要原因是当服务端收到客户端的 FIN 数据包后,服务端可能还有数据没发完,不会立即close。
所以服务端会先将 ACK 发过去告诉客户端我收到你的断开请求了,但请再给我一点时间,这段时间用来发送剩下的数据报文,发完之后再将 FIN 包发给客户端表示现在可以断了。之后客户端需要收到 FIN 包后发送 ACK 确认断开信息给服务端。
了解REST API吗
REST API全称为表述性状态转移(Representational State Transfer,REST)即利用HTTP中get、post、put、delete以及其他的HTTP方法构成REST中数据资源的增删改查操作:
- Create : POST
- Read : GET
- Update : PUT/PATCH
- Delete: DELETE
简述SYN攻击
SYN攻击即利用TCP协议缺陷,通过发送大量的半连接请求,占用半连接队列,耗费CPU和内存资源。
优化方式:
缩短SYN Timeout时间
记录IP,若连续受到某个IP的重复SYN报文,从这个IP地址来的包会被一概丢弃。
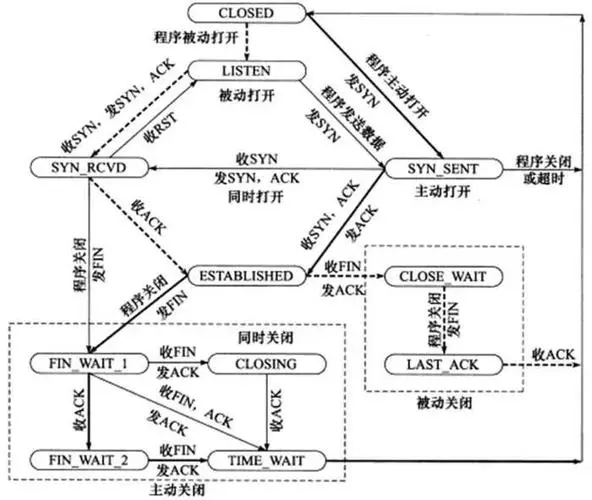
TCP四次挥手过程
第一次挥手:客户端发送一个FIN,用来关闭客户端到服务端的数据传送,客户端进入finwait1状态。
第二次挥手:服务端收到FIN后,发送一个ACK给客户端,确认序号为收到序号+1,服务端进入Close_wait状态。此时TCP连接处于半关闭状态,即客户端已经没有要发送的数据了,但服务端若发送数据,则客户端仍要接收。
第三次挥手:服务端发送一个FIN,用来关闭服务端到客户端的数据传送,服务端进入Last_ack状态。
第四次挥手:客户端收到FIN后,客户端进入Time_wait状态,接着发送一个ACK给服务端,确认后,服务端进入Closed状态,完成四次挥手。
简述快重传
如果在超时重传定时器溢出之前,接收到连续的三个重复冗余ACK,发送端便知晓哪个报文段在传输过程中丢失了,于是重发该报文段,不需要等待超时重传定时器溢出再发送该报文。
简述HTTP短连接与长连接区别
HTTP中的长连接短连接指HTTP底层TCP的连接。
短连接: 客户端与服务器进行一次HTTP连接操作,就进行一次TCP连接,连接结束TCP关闭连接。
长连接:如果HTTP头部带有参数keep-alive,即开启长连接网页完成打开后,底层用于传输数据的TCP连接不会直接关闭,会根据服务器设置的保持时间保持连接,保持时间过后连接关闭。
简述cookie
HTTP 协议本身是无状态的,为了使其能处理更加复杂的逻辑,HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie是由服务端产生的,再发送给客户端保存,当客户端再次访问的时候,服务器可根据cookie辨识客户端是哪个,以此可以做个性化推送,免账号密码登录等等。
简述TCP/IP五层协议
TCP/IP五层协议包括:物理层,数据链路层,网络层,运输层,应用层
简述OSI七层协议
OSI七层协议包括:物理层,数据链路层,网络层,运输层,会话层,表示层, 应用层
对于UDP包,如果MTU = 1500,那么udp payload最大值是多少,才可以不用分片?
MTU(1500) = IPHeader(20) + UDPHeader(8) + Data
Data = 1500 -20 - 8 = 1472
如果UDP包的Data <= 1472个字节,UDP包(UDPHeader+Data)在网络层不用分片,直接封装上IPHeader发往链路层
如果UDP包的payload > 1472,那么UDP包(UDPHeader + Data)在网络层需要分片,如何分片?
网络层并不会在每个分片里复制一次UDP头,它是把完整的UDP包切开,加上IP头发送出去,除了第一个分片有UDP头,后面的分片都不包含UDP头
如果MTU是1500,Client发送一个8000字节大小的UDP包,那么Server端阻塞模式下接包,在不丢包的情况下,recvfrom(9000)是收到1500,还是8000。如果某个IP分片丢失了,recvfrom(9000),又返回什么呢?
根据UDP通信的有界性,在buf足够大的情况下,接收到的一定是一个完整的数据包,UDP数据在下层的分片和组片问题由IP层来处理,提交到UDP传输层一定是一个完整的UDP包,那么recvfrom(9000)将返回8000。如果某个IP分片丢失,udp里有个CRC检验,如果包不完整就会丢弃,也不会通知是否接收成功,所以UDP是不可靠的传输协议,那么recvfrom(9000)将阻塞。
tc qdisc add dev eth0 root netem loss 50%
tc qdisc del dev eth0 root
tc qdisc add dev eth0 root tbf rate 500kbit burst 10kb latency 50ms
tc qdisc del dev eth0 root
dev eth0:指定要限制速度的网络接口。
root:指定这是在根队列上进行配置。
tbf:使用令牌桶过滤器(Token Bucket Filter)来进行流量控制。
rate 500kbit:设置上传速度限制为 500Kbps。
burst 10kb:设置允许的突发数据量为 10KB。
latency 50ms:设置最大延迟为 50毫秒。
这里首先要说下:MSS(Maxitum Segment Size)最大分段大小,它是 TCP 协议里面的一个概念。
TCP 在建立连接的时候,会协商双方的MSS值,通常这个 MSS 会控制在 MTU 以内:最大 IP 包大小减去 IP 和 TCP 协议头的大小。(其最终目的:就是尽量避免 IP 分片)
这样 TCP 就可以在自己这一层,把用户发送的数据,预先分成多个大小限制在 MTU 里的 TCP 包。每个 TCP 的分段,都完整了包含了 TCP 头信息,方便在接收方重组。
如果某些情况导致:已经分好的 TCP 分段,还是大于了 MTU,那就在 IP 层中,再执行一次分片。
这个时候如果数据丢了,那也只需要重传这一个 TCP 的分段,而不是整个原始的 50k 数据。

IP 包头部中有 3 个与分片相关的字段,分别是:
- 标识符( identification ),IP 包的 ID ,全局自增,短时间内不会重复,可唯一标识一个 IP 包;
- 标志位( flags ),包括两个用于控制和识别分片的标志位;
- DF 标志位禁止中间路由对该包进行分片;
- MF 标志位表明该包之后还有其他分片;
- 偏移量( fragment offset ),表示一个分片相对于原始 IP 包开头的偏移量,以 8 字节为单位;
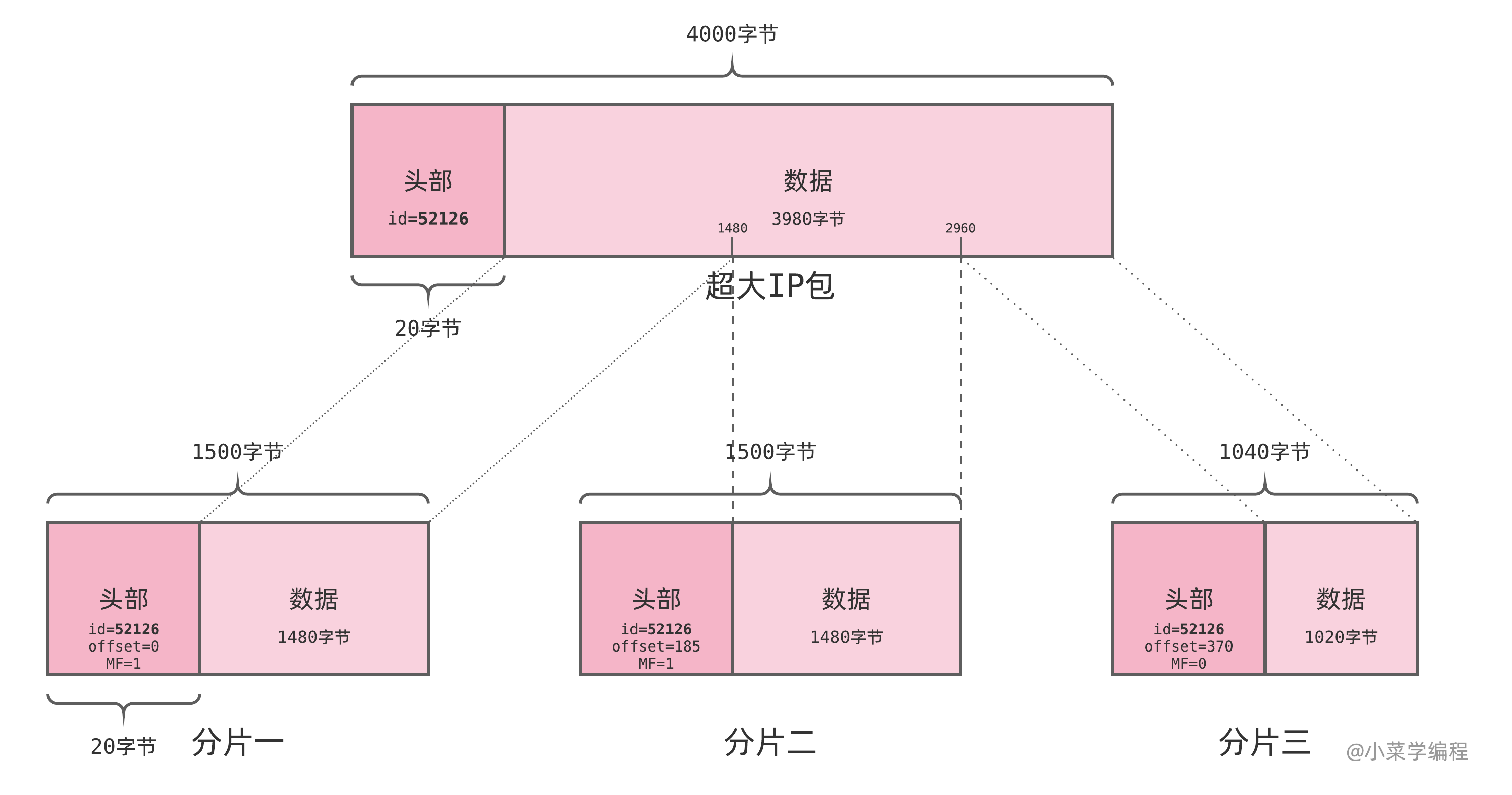
分片到达目标主机后,系统根据包头中的源地址、目的地址、标识符、偏移量等字段,将它们重组合成原包。实际上,系统会分配一块内存作为重组分片的缓冲区。一个分片包首个分片达到后,系统将其移入到该缓冲区,等待其他分片达到:后续分片达到后,系统先根据源地址、目的地址和标识符确定它属于哪个包;再根据偏移量确定它属于原包的哪个部分;最后将分片数据拼接到原包中。当所有分片都到达后,原包也就成功重组出来了!
如果中间路由链路 MTU 变小,经过的 IP 包大小超出限制,路由便再次对 IP 包进行分片。就算 IP 包已分过片,只要有分片大小超出限制,都要进一步划分:中间路由只会对 IP 包进行分片,不会对分片进行重组。如上图, IP 包来到 R2 后链路 MTU 变大,理论上可以对前两个分片进行组装,还原出原来的分片 1 。但出于效率考虑,中间路由不会这么做,分片只有到达目的地即主机②之后,才会开始重组。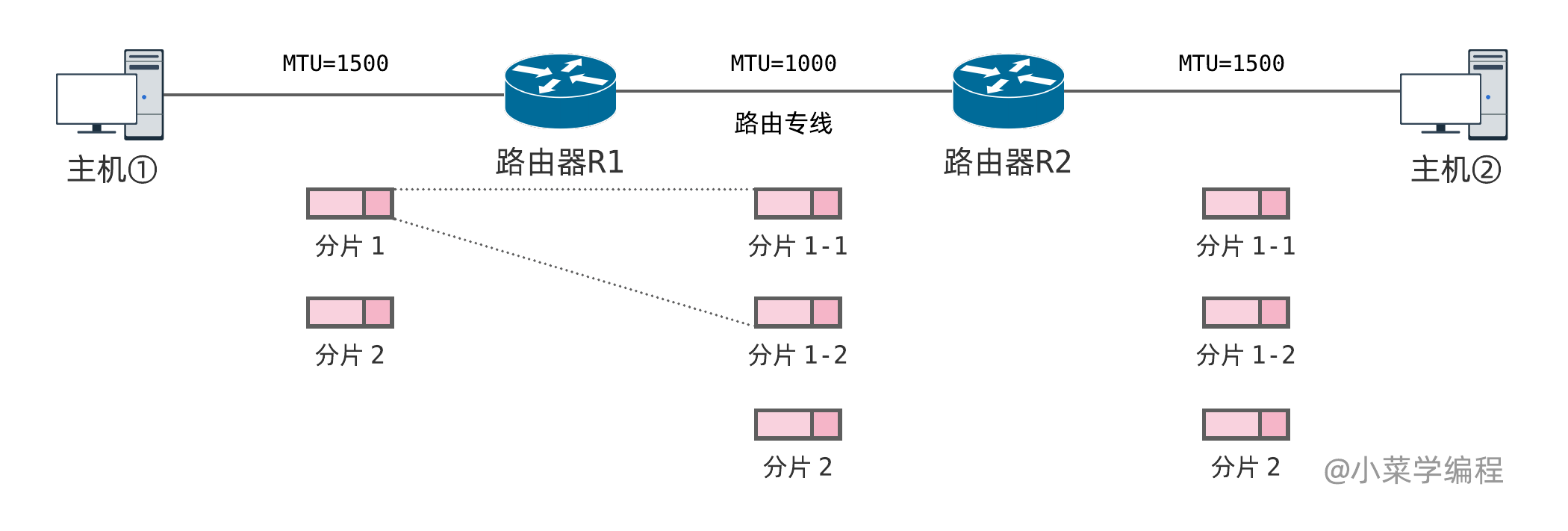
会话层有什么作用
建立会话:身份验证,权限鉴定等; 保持会话:对该会话进行维护,在会话维持期间两者可以随时使用这条会话传输局; 断开会话:当应用程序或应用层规定的超时时间到期后,OSI会话层才会释放这条会话。
简述TCP协议的拥塞控制
拥塞是指一个或者多个交换点的数据报超载,TCP又会有重传机制,导致过载。 为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量.
当cwnd < ssthresh 时,使用慢开始算法。 当cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。 当cwnd = ssthresh 时,即可使用慢开始算法,也可使用拥塞避免算法。
慢开始:由小到大逐渐增加拥塞窗口的大小,每接一次报文,cwnd指数增加。
拥塞避免:cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1。
快恢复之前的策略:发送方判断网络出现拥塞,就把ssthresh设置为出现拥塞时发送方窗口值的一半,继续执行慢开始,之后进行拥塞避免。
快恢复:发送方判断网络出现拥塞,就把ssthresh设置为出现拥塞时发送方窗口值的一半,并把cwnd设置为ssthresh的一半,之后进行拥塞避免。
数据链路层有什么作用
在不可靠的物理介质上提供可靠的传输,接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层。这一层在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路。提供物理地址寻址功能。交换机工作在这一层。
为何TCP可靠
TCP有三次握手建立连接,四次挥手关闭连接的机制。 除此之外还有滑动窗口和拥塞控制算法。最最关键的是还保留超时重传的机制。 对于每份报文也存在校验,保证每份报文可靠性。
转发和重定向的区别
转发是服务器行为。服务器直接向目标地址访问URL,将相应内容读取之后发给浏览器,用户浏览器地址栏URL不变,转发页面和转发到的页面可以共享request里面的数据。
重定向是利用服务器返回的状态码来实现的,如果服务器返回301或者302,浏览器收到新的消息后自动跳转到新的网址重新请求资源。用户的地址栏url会发生改变,而且不能共享数据。
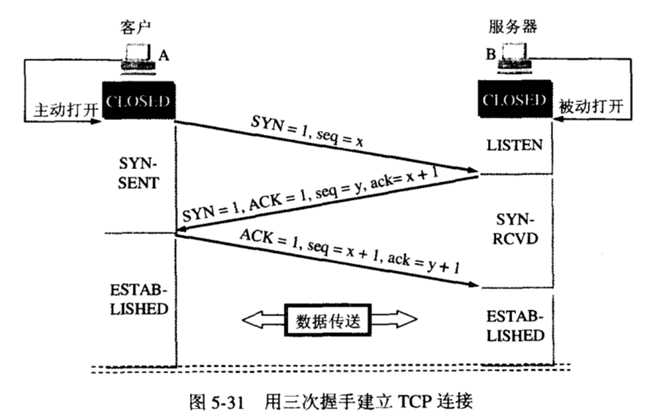
TCP三次握手过程
第一次握手:客户端将标志位SYN置为1,随机产生一个值序列号seq=x,并将该数据包发送给服务端,客户端 进入syn_sent状态,等待服务端确认。
第二次握手:服务端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务端将标志位SYN和 ACK都置为1,ack=x+1,随机产生一个值seq=y,并将该数据包发送给客户端以确认连接请求,服务端进入syn_rcvd状态。
第三次握手:客户端收到确认后检查,如果正确则将标志位ACK为1,ack=y+1,并将该数据包发送给服务端,服务端进行检查如果正确则连接建立成功,客户端和服务端进入established状态,完成三次握手,随后客户端和服务端之间可以开始传输 数据了
简述http状态码和对应的信息
1XX:接收的信息正在处理
2XX:请求正常处理完毕
3XX:重定向
4XX:客户端错误
5XX:服务端错误
常见错误码: 301:永久重定向 302:临时重定向 304:资源没修改,用之前缓存就行 400:客户端请求的报文有错误 403:表示服务器禁止访问资源 404:表示请求的资源在服务器上不存在或未找到
简述TLS/SSL, HTTP, HTTPS的关系
SSL全称为Secure Sockets Layer即安全套接层,其继任为TLSTransport Layer Security传输层安全协议,均用于在传输层为数据通讯提供安全支持。
可以将HTTPS协议简单理解为HTTP协议+TLS/SSL
简述DNS解析过程
1、客户机发出查询请求,在本地计算机缓存查找,若没有找到,就会将请求发送给dns服务器
2、本地dns服务器会在自己的区域里面查找,找到即根据此记录进行解析,若没有找到,就会在本地的缓存里面查找
3、本地服务器没有找到客户机查询的信息,就会将此请求发送到根域名dns服务器
4、根域名服务器解析客户机请求的根域部分,它把包含的下一级的dns服务器的地址返回到客户机的dns服务器地址
5、客户机的dns服务器根据返回的信息接着访问下一级的dns服务器
6、这样递归的方法一级一级接近查询的目标,最后在有目标域名的服务器上面得到相应的IP信息
7、客户机的本地的dns服务器会将查询结果返回给我们的客户机
8、客户机根据得到的ip信息访问目标主机,完成解析过程
Get方法参数有大小限制吗
一般HTTP协议里并不限制参数大小限制。但一般由于get请求是直接附加到地址栏里面的,由于浏览器地址栏有长度限制,因此使GET请求在浏览器实现层面上看会有长度限制。
为何UDP不可靠
UDP面向数据报无连接的,数据报发出去,就不保留数据备份了。 仅仅在IP数据报头部加入校验和复用。 UDP没有服务器和客户端的概念。 UDP报文过长的话是交给IP切成小段,如果某段报废报文就废了。
表示层有什么作用
对数据格式进行编译,对收到或发出的数据根据应用层的特征进行处理,如处理为文字、图片、音频、视频、文档等,还可以对压缩文件进行解压缩、对加密文件进行解密等。
浏览器中输入一个网址后,具体发生了什么
进行DNS解析操作,根据DNS解析的结果查到服务器IP地址
通过ip寻址和arp,找到服务器,并利用三次握手建立TCP连接
浏览器生成HTTP报文,发送HTTP请求,等待服务器响应
服务器处理请求,并返回给浏览器
根据HTTP是否开启长连接,进行TCP的挥手过程
浏览器根据收到的静态资源进行页面渲染
Reactor和Proactor是两种不同的I/O事件处理模式:
- Reactor模式:基于事件驱动的设计,将I/O事件分发给对应的事件处理程序。这种模式中,有一个轮询器(Dispatcher)负责监视所有资源的状态,并通知相关的事件处理程序。Reactor是同步的,也就是说在读取或写入时,程序会阻塞直到完成请求。这种模式适用于处理少量活动连接或短期的I/O操作。
- Proactor模式:与Reactor不同,Proactor是异步的,即客户端请求被提交后,程序继续工作而不阻塞等待请求完成。这种模式中,客户端提交一个请求,I/O操作被提交给操作系统,当执行完成时,操作系统将结果通知应用程序,然后执行后续操作。因此,Proactor模式可以更好地处理大量连接或复杂的I/O。
综上所述,Reactors适用于处理少量的I/O,而Proactors可以处理大量或长期的I/O操作。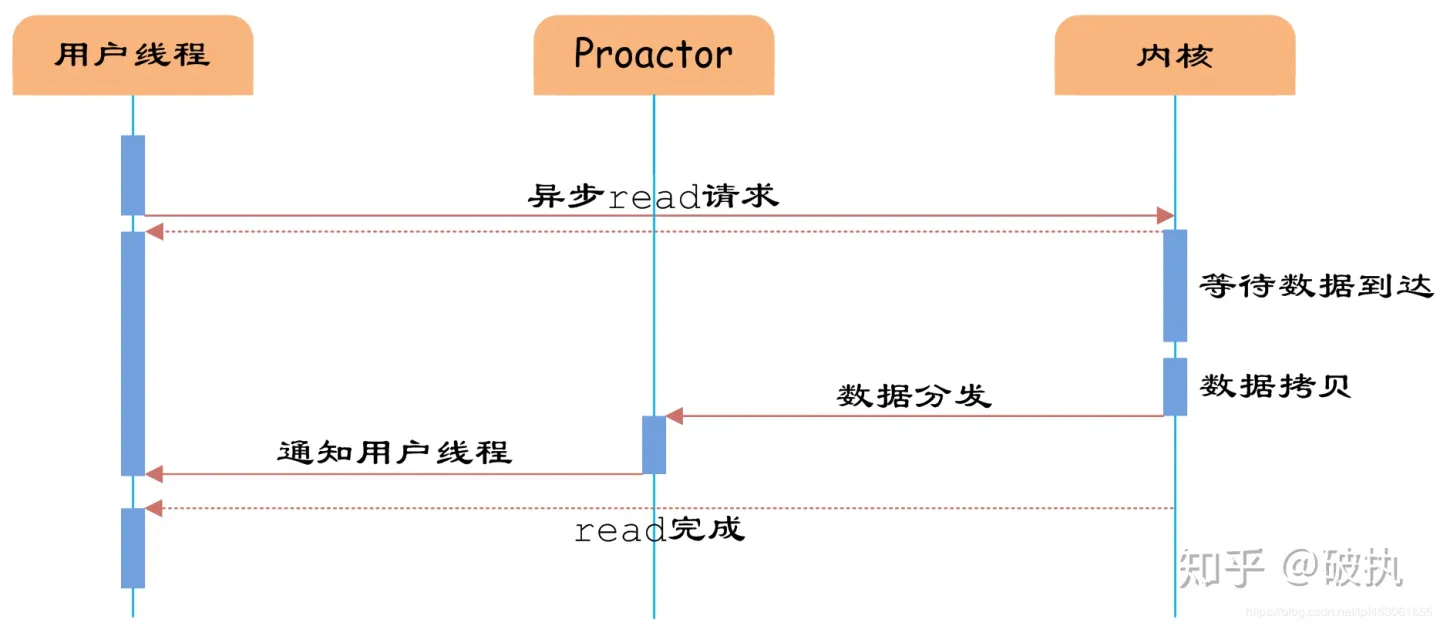
TCP是一种可靠的传输协议,但是由于它的连接管理过程中存在一些攻击漏洞,因此会面临一些安全问题,以下是可能的攻击漏洞:
- SYN Flood攻击:攻击者发送大量伪造的TCP连接请求(SYN包),占用服务器的大量资源,使其无法响应合法的连接请求,达到拒绝服务(DoS)的目的。
- TCP Reset攻击:攻击者发送TCP RST包,关闭两个正在通信的主机之间的连接。如果攻击者能够伪造TCP RST包,就可以终止合法连接。
- TCP序列号预测攻击:攻击者猜测TCP序列号,从而成为中间人,篡改数据,对数据进行劫持和窃听。如果攻击者能够猜测TCP序列号,则可以创建伪造的连接、篡改数据或执行其他恶意行为。
- TCP上的会话劫持:攻击者能够截取一台计算机和另一台计算机之间的TCP连接,并且能够读取、修改、替换或使用这些连接上发送的信息。
为防止这些攻击,TCP协议的实现者需要采用一些必要的安全措施,例如使用随机序列号来防范序列号预测攻击,对连接请求进行频率限制来防止SYN Flood攻击,使用加密协议以确保会话安全,以及使用防火墙和入侵检查系统来防止攻击者的进入和攻击。
幂等性是指对于同一操作,无论执行多少次,结果都是单一的。在HTTP协议中,幂等性指的是通过HTTP方法执行的操作所具有的这种特性。以下是HTTP协议中具有幂等性的方法:
- GET方法:它只负责获取资源,对同一个URL的多次请求获得的结果是相同的,因此是幂等的。
- HEAD方法:类似于GET方法,但只返回响应头信息,而不返回响应实体主体。
- PUT方法:用于更新服务器上的资源,如果多次执行相同的PUT请求,其结果是相同的,因此PUT方法也是幂等的。
- DELETE方法:用于从服务器上删除资源,多次执行相同的DELETE请求所得到的结果是相同的,因此也是幂等的。
HTTP1.0 HTTP1.1 HTTP2.0,这三个有什么区别及其改进
HTTP1.0是最早的HTTP版本,它只支持每个TCP连接同时传递一个请求,并且每个请求必须等待前一个请求的回复才能继续传输,因此效率稍低。
HTTP1.1是HTTP协议的第二个版本,它引入了持久连接、分块传输编码和HTTP头部信息压缩等技术,大大提高了HTTP协议的效率和性能。
HTTP2.0则进一步改进了HTTP1.1,引入了二进制格式传输、多路复用和服务端推送等新特性,使得HTTP协议更加快速和高效,提高了网站的响应速度和性能。
HTTPS使用对称加密和非对称加密的组合来保证通信的安全。在TLS通信开始之前,客户端和服务器会协商一个会话密钥,并使用非对称加密算法进行加密。然后,客户端使用这个密钥与服务器进行加密通信。
Linux防火墙策略配置可以使用iptables命令完成。以下是一些常见的策略配置:
- 允许特定端口的进出流量: 其中,{port}为需要允许的端口号。
1
2
3iptables -A INPUT -p tcp --dport {port} -j ACCEPT
iptables -A OUTPUT -p tcp --sport {port} -j ACCEPT
iptables -D INPUT -p tcp -m tcp --dport 9904 -m comment --comment proxy -j ACCEPT - 允许指定IP地址段的进出流量: 其中,{ip_address}为需要允许的IP地址。
1
2iptables -A INPUT -s {ip_address}/24 -j ACCEPT
iptables -A OUTPUT -d {ip_address}/24 -j ACCEPT - 不允许所有其他流量通过: 以上策略配置示例中,INPUT表示入站流量,OUTPUT表示出站流量。-p参数指定协议类型,–dport和–sport参数分别指定目标端口和源端口,-s和-d参数分别指定源IP地址和目标IP地址。-j参数指定对匹配规则的处理动作,ACCEPT表示允许流量通过,DROP表示阻止流量通过。
1
2iptables -A INPUT -j DROP
iptables -A OUTPUT -j DROP
在Linux中进行路由配置的常用方法包括:
- 使用route命令:route命令可以用于显示和修改Linux内核IP路由表,例如添加、删除或修改路由规则。例如,在终端输入以下命令添加一条默认路由规则:
sudo route add default gw 192.168.1.1,其中,192.168.1.1是网关的IP地址。route -n命令输出两条路由规则,每条占一行,分别有目的地、网关、子网掩码、标志位以及出口设备等好几列。其中,目的地结合子网掩码确定目的网段,例如 192.168.1.0/255.255.255.0 表示 192.168.1.x 这个网段。
1 | root@ant [ ~ ] ➜ route -n |
第一条路由记录(第 4 行)的意思是,去往 192.168.1.x 网段的 IP 包,都可以通过 eth0 直接发送出去。网关 0.0.0.0 表示 IP 包无须通过任何路由中介进行转发,也就是说 192.168.1.x 网段是一个本地网段,可以直接通信。
第二条路由记录(第 5 行)的意思是,去往 192.168.2.x 网段的 IP 包,需要先发给 192.168.1.1 ,由它负责转发;而网关 192.168.1.1 可以通过 eth0 网卡直接通信。
2. 使用ip命令:ip命令是较新版本的Linux系统中使用的工具,它也可以用于管理网络接口和路由表,ip 是一个比较新的命令,更推荐使用。例如,以下命令可以添加一个名为eth0的网络接口,并将其IP地址设置为192.168.1.2:
sudo ip addr add 192.168.1.2/24 dev eth0
同样,以下命令可以添加一条默认路由规则:
sudo ip route add default via 192.168.1.1
其中,192.168.1.1是网关的IP地址。
1 | root@ant [ ~ ] ➜ ip route |
192.168.1.0/24 是子网掩码的另一种表示法,代表 192.168.1.x 这个网段。
第一条路由的意思是,去往 192.168.1.x 网段的 IP 包,可以直接从 eth0 网卡中发送出去;第二条路由则表示,去往 192.168.2.x 也可以通过 eth0 网卡发送,但必须先发给 192.168.1.1 ,由它负责转发。
| 路由种类 | 通信场景 | route命令特征 | ip命令特征 |
|---|---|---|---|
| 直接路由 | 本地网通信 | 网关为空,即0.0.0.0;标志位不带G 不带via | |
| 间接路由 | 网际通信 | 网关非空;标志位带G 带via |
主机 ant 可以通过以太网,向网络中的其他主机发出广播,询问 192.168.1.2 这个 IP 的 MAC 地址。ff:ff:ff:ff:ff:ff 是一个特殊的广播地址,目的地址为 ff:ff:ff:ff:ff:ff 的以太网帧,将被送到以太网中的每一台主机。交换机收到目的地址为 ff:ff:ff:ff:ff:ff 的帧后,也会将它广播到所有端口:


tcpdump是一个命令行工具,它可以监听网络接口并捕获数据包。以下是使用tcpdump进行网络分析的基本步骤:
安装并打开tcpdump:tcpdump通常已经预装在Linux、Unix和MacOS等系统中,如果没有安装可以通过包管理器进行安装。在终端中输入命令tcpdump即可启动tcpdump。
选择要监视的网络接口:在tcpdump中,可以通过指定网络接口来选择要监听的网络流量。例如,如果要监听eth0接口的数据包可以使用以下命令:
sudo tcpdump -i eth0
分析捕获的数据包:当数据包被捕获时,它们会显示在终端中。可以按照不同协议、源地址、目标地址等条件过滤数据包,并查看每个数据包的详细信息。
将捕获的数据包保存到文件:可以使用以下命令将数据包保存到文件中以供后续分析:
sudo tcpdump -i eth0 -w packets.pcap
tcpdumpx=’tcpdump -x -vv -s0 -iany’
以上命令将捕获eth0接口的数据包,并将其保存到名为packets.pcap的文件中。可以在Wireshark等抓包工具中打开该文件进行进一步分析。
tcpdump -i any -nn -s 0 -A udp port 53 域名解析域名过滤
1 | root@ant [ ~ ] ➜ traceroute -n 10.0.2.2 |
从 traceroute 命令的输出,我们可以获悉去往 10.0.2.2 时,需要经过 4 跳:
- 第 1 跳是 10.0.1.1 ,即路由器 R1 ;
- 第 2 跳是 10.2.0.1 ,即路由器 R2 ;
- 第 3 跳是 10.4.0.1 ,即路由器 R3 ;
- 最后一跳是目的地 10.0.2.2 ,即主机 apple 本身;
IP 包每经过一跳路由, TTL 减一;当 TTL 减到零,路由器便将它丢弃。这样可避免 IP 包因陷入路由环路而在网络中永远存在。路由器在将超时包丢弃的同时,负责向源 IP 发送一个 ICMP 报文,报告 传输超时 ( time to live exceeded in transit )错误,ICMP 类型为 11 。
- traceroute 发出第五个探测包,序号为 5 , TTL 为 2 ,并将对应关系保存在映射表;
- 该探测包是一个 ICMP 回显请求,类型为 8 ,目的地址 10.0.2.2 为探测目标 apple ;
- 该包走到第二跳路由 R2 时,TTL 就耗尽了,路由 R2 向原包发送方报告超时差错;
- 路由将原探测包的 IP 头部和数据前 8 字节( ICMP 头部)作为数据附在 ICMP 差错报文中;
- 差错包到达主机 ant 后,traceroute 取出差错包中附带的原探测包的头部;
- 检查原探测包 ICMP 头部中的标识符字段,traceroute 确认原探测包是自己发的(区分其他进程);
- 根据原探测包 ICMP 头部中的序号字段,traceroute 从映射表中查到原探测包的 TTL 为 2;
- traceroute 确定该差错包是第 2 跳路由发来的,源地址 10.2.0.1 就是路由的地址;

递归解析器需要从根服务器开始,逐层查询,这个过程是 迭代解析 。如果不想通过递归解析器,可以自行执行迭代解析。
- 客户端向本地的递归解析器查询域名 www.fasionchan.com ;
- 递归解析器向根域名服务器查询域名 www.fasionchan.com ;
- 根域名服务器告诉递归解析器,应该去找 .com 的顶级域名服务器;
- 递归解析器向顶级域名服务器查询域名 www.fasionchan.com ;
- 顶级域名服务器告诉递归解析器,应该去找 fasionchan.com 的权威域名服务器;
- 递归解析器向权威域名服务器查询域名 www.fasionchan.com ;
- 权威服务器向递归解析器返回结果;
- 递归解析器向客户端返回结果;
- 客户端拿到域名对应的 IP 地址后,即可向该 Web 服务器发起请求;
- Web 服务器处理请求后,向客户端返回结果;