stable diffusion整理
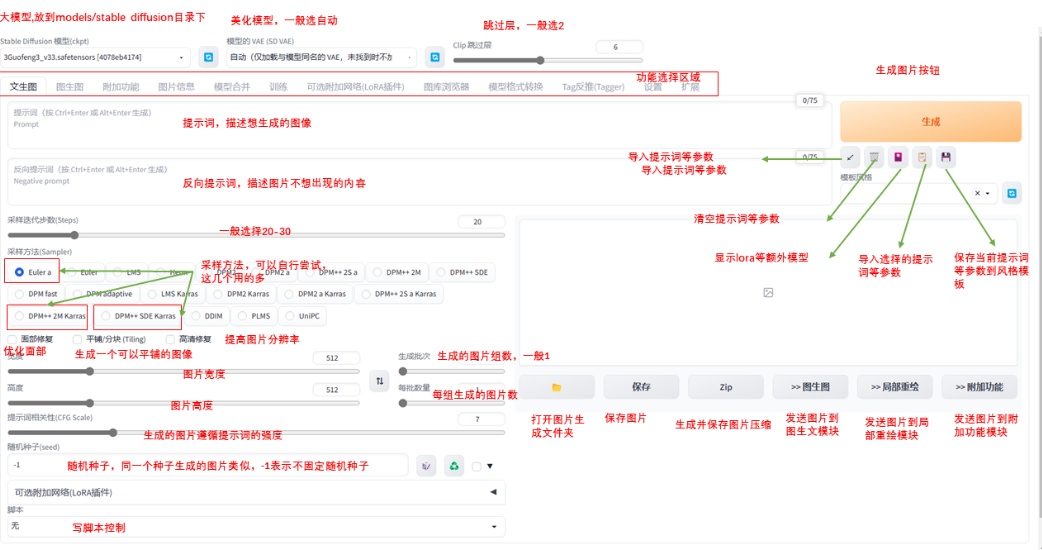
模型
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
https://www.liblib.art/
真人图片就用:
majicmixRealistic,chilloutmix
其他就用:
revAnimated,realisticVision,deliberate
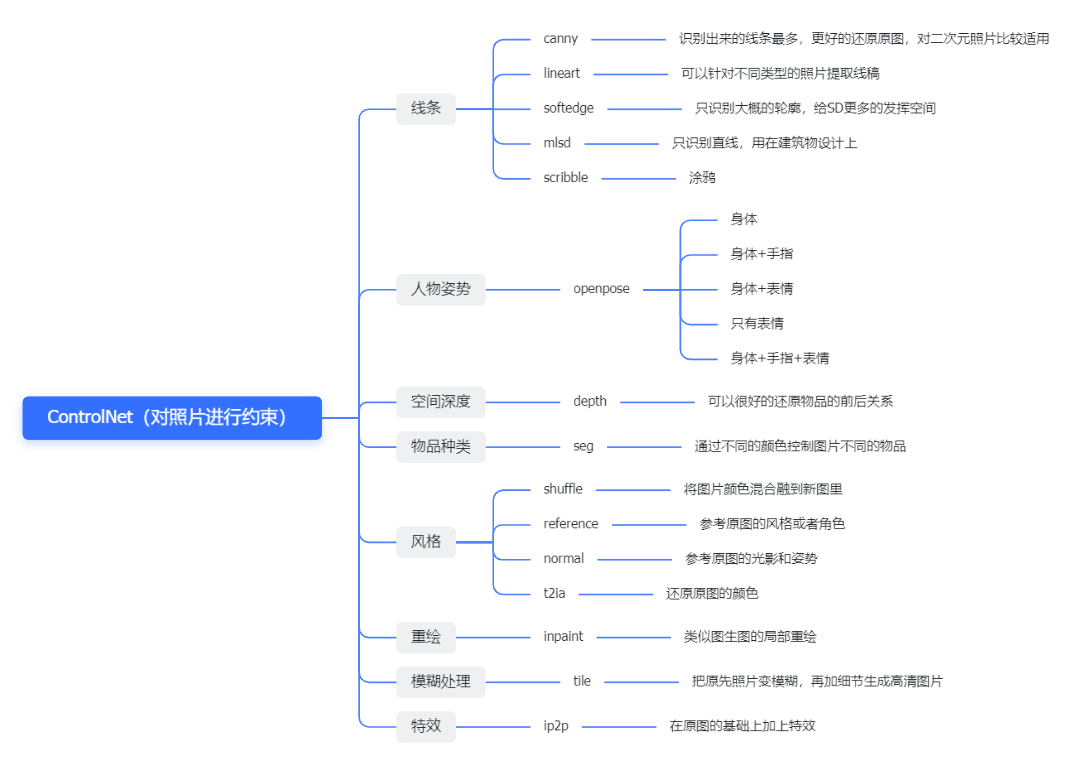
ControlNet负责更好地“控制”这个“模型”或画面,ControNet的作用是精细化控制整体图片的元素——主体、背景、风格、形式等,ControlNet就是你提供一张图片,然后选择一种采集方式,去生成一张新的图片
- 可以选择采集图片中人物的骨架,从而在新的图片中生成出一样姿势的人
- 可以选择采集图片中画面的线稿,从而在新的图片中生成一样线稿的画面
- 可以选择采集图片中已有的风格,从而在新的图片中生成一样风格的画面
Lora负责把想要画面的“主体”或“场景”炼制成模型,Lora的作用是让图片主体符合我们的需求
CheckPoint模型
主模型,包含了很多场景素材,所以体积很大,其它模型都是在它基础上做一些细节的定制
- openpose 模型 用于控制人物姿势,可通过参考图(或骨架图)片生成同样姿势的人物
- lineart是一个专门提取线稿的模型,可以针对不同类型的图片进行不同的处理
- canny 模型可以检测图片的边缘,并提取成线稿图,然后根据这个线稿图作图。所以他不仅可以控制任务姿势,还能控制图片中出现的其它元素的外形。canny可以识别到画面的最多的线条,这样就可以最大程度的还原照片,但是比较适合二次元照片
- softedge只能识别图片大概的轮廓细节,线条比较柔和,这样给SD发挥的空间就比较大
- depth是一个深度检测模型,可以检测图片先后的位置空间关系,生成深度图,并根据深度图作图。缺点是人物细节没有捕捉到,可以看到深度图里面几乎没有人物身体细节信息。能够很好的复刻房子线条,而且物品的距离镜头的前后顺序比较清晰。
- hed 也是一个边缘检测算法,跟canny类似。但hed算法生成的线稿图线条比较粗,细节得到了补充。
- mlsd模型可以提取图片中的线段,适用于建筑和室内设计等场景,不适用于人物;这个模型只能识别直线,所以只适合拿来做房子的设计
- normal模型,可以很好的捕捉空间关系,也能捕获轮廓内部的特征,生成类型模型的图片,并以此作图。可以看到比depth算法轮廓内部细更丰富。
- scribble 以涂鸦的方式,提取出照片中物体为黑白稿,并根据黑白稿作图;可以将自己随便画的东西放进去,通过输入关键词得到有着一样线条的照片
- seg模型的作用是提取图片中的不同物体,标记成不同的颜色,并根据语义图作图;识别图片不一样的东西,就用不同的颜色表示
- shuffle 将其他图片的画风转移到自己的照片上;首先先用大模型和关键词生成一张自己喜欢的图片,固定随机数种子,然后打开controlnet将别的照片画风转移到自己的照片
- reference 可以很好的还原原图的角色;如让坐着的小狗跑起来,给SD一张人物角色图,它会根据人物的五官、发型还原这个人物
- Normal 这个模型可以参考原图的明暗关系,并且还原原图的姿势
- inpaint 和图生图里的局部重绘差不多,但是inpaint可以将重绘的地方跟原图融合的更好一点,如给人物换衣服
- ip2p 给照片加特效,比如让房子变成冬天、让房子着火
- tile 加照片细节,恢复画质;但是这个恢复画质的方法可能不太适合真人,先忽略掉照片的一些细节,再加上一些细节,这些SD自己加上去的细节可能会导致生成出来的照片不像原图;涂鸦,将自己画的图给SD加工;真人变动漫;动漫变真人
- qrcode_monster,二维码
- brightness/illumination
lora模型
微调模型:主要用来定制人物,轻巧,训练高效
VAE模型
美化模型: 主要用来美化图片色彩,很多主模型已经自带
Embedding模型
嵌入模型:主要用来调教文本理解能力
Hypernetwork模型
超网络模型:主要用来定制画风、风格
关键字
一般来说越靠前的词汇权重就会越高,比如说
- car,1girl, 可能会出现一整辆车,旁边站着女孩
- 1girl,car, 可能会出现女孩肖像,背景是半辆车
所以多数情况下的提示词格式是:质量词,媒介词,主体,主体描述,背景,背景描述,艺术风格和作者
- 质量:代表画面的品质,如1girl 结合 high quality 使用来获得高质量图像。
- 主体:画面主要内容,这是任何提示的基本组成部分
- 代表动作/场景:描述了主体在哪里做了什么。
- 风格:画面风格(可选)
- 细节补充:可以使用 艺术家,工作室,摄影术语,角色名字,风格,特效等等
最直接的权重调节就是调整词语顺序,越靠前权重越大,越靠后权重越低
可以通过下面的语法来对关键词设置权重,一般权重设置在0.5~2之间,可以通过选中词汇,按ctrl+↑↓来快速调节权重,每次步进为0.1
- (best quality:1.3)
1 | best quality, masterpiece, highres, 1girl,blush,(seductive smile:0.8),star-shaped pupils,china hanfu,hair ornament,necklace, jewelry,Beautiful face,upon_body, tyndall effect,photorealistic, dark studio, rim lighting, two tone lighting,(high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, volumetric lighting, candid, Photograph, high resolution, 4k, 8k, Bokeh |
城市建筑:
1 | Best quality, ultra high definition, masterpiece, ultimate details, 8K, |
人物:
1 | The highest quality, masterpiece, ultimate detail, |
幻字
1 | best quality, masterpiece, highres, |
采样方法
- Euler a:速度最快的采样方式,对采样步数要求很低,同时随着采样步数增加并不会增加细节,会在采样步数增加到一定步数时构图突变,所以不要在高步数情景下使用
- DPM++2S a Karras 和 DPM++ SDE Karras:这两个差不太多,似乎SDE的更好,总之主要特点是相对于Euler a来说,同等分辨率下细节会更多,比如可以在小图下塞进全身,代价是采样速度更慢
- DDIM: 很少会用到,但是如果想尝试超高步数可以使用,随着步数增加可以叠加细节
一般来说大部分时候采样部署只需要保持在20~30之间即可,更低的采样部署可能会导致图片没有计算完全,更高的采样步数的细节收益也并不高,只有非常微弱的证据表明高步数可以小概率修复肢体错误,所以只有想要出一张穷尽细节可能的图的时候才会使用更高的步数
提示词相关性(CFG)
CFG很难去用语言去描述具体的作用,很笼统的来说,就是给你所有的正面和反面提示词都加上一个系数,所以一般CFG越低,画面越素,细节相对较少,CFG越高,画面越腻,细节相对较多
- 二次元风格CFG可以调的高一些以获得更丰富的色彩和质感表达,一般在7
12,也可以尝试1220 - 写实风格CFG大都很低,一般在4~7,写实模型对CFG很敏感,稍微调多一点可能就会古神降临,可以以0.5为步进来细微调节
随机种子
随机种子可以锁定这张图的初始潜在空间状态,意思就是如果其他参数不变,同一个随机种子生成的图应该是完全相同的,可以通过锁定随机种子来观察各种参数对画面的影响,也可以用来复现自己和他人的画面结果
- 点击筛子按钮可以将随机种子设为-1,也就是随机
- 点击回收按钮可以将随机种子设为右边图片栏里正在看的那张图片的随机种子