thrift源码分析
+——————————————-+
| Server |
| (single-threaded, event-driven etc) |
+——————————————-+
| Processor |
| (compiler generated) |
+——————————————-+
| Protocol |
| (JSON, compact etc) |
+——————————————-+
| Transport |
| (raw TCP, HTTP etc) |
+——————————————-+
Transport
Transport传输层为从网络读取/向网络写入提供了一个简单的抽象。这使 Thrift 能够将底层传输与系统的其余部分分离(例如,序列化/反序列化)
Transport接口:
- open
- close
- read
- write
- flush
除了上面的 Transport 接口之外,Thrift 还使用了一个 ServerTransport 接口,用于接受或创建原始传输对象。顾名思义,ServerTransport 主要用于服务器端,为传入连接创建新的传输对象
midjourney
https://docs.midjourney.com/docs/invite-the-bot,可以将机器人拉入到自己的群中,这样消息不会被淹没。
api下载mj生成的图片:https://medium.com/@neonforge/how-to-create-a-discord-bot-to-download-midjourney-images-automatically-python-step-by-step-guide-3e76d3282871
api自动发送mj消息:https://medium.com/@neonforge/how-to-automate-midjourney-image-generation-with-python-and-gui-automation-ac9ca5f747ae
discord生成应用:https://discord.com/developers/applications
discord开发手册:https://discord.com/developers/docs/interactions/application-commands
1 | Action shot.An Asian little boy sitting on a flying pterosaur .Close-Up.surreal photography. |
网站seo优化
网页重定向
网页迟迟没有被google收录,进入https://search.google.com/发现: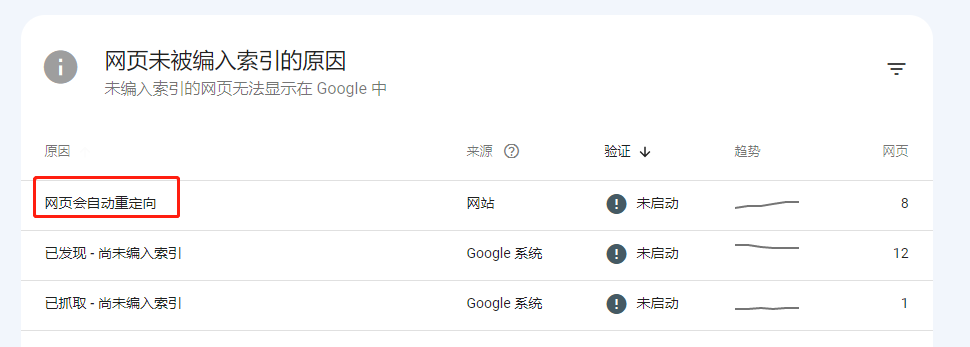
在 Nuxt.js 中,您可以通过设置 generate.subFolders 选项来控制生成的文件是否应该包含子目录。默认情况下,该选项的值为 true,这意味着生成的文件将被放置在相应的路由目录中。
如果您不想要生成的文件包含子目录,并直接生成 HTML 文件,您可以将 generate.subFolders 设置为 false。您可以在 nuxt.config.js 文件中添加以下配置:
1 | export default { |
ThreadManager实现
服务器TNonblockingServer
rpc请求生成task放入到任务队列中,这个任务是Runnable的,但没有依附于某个thread,等于是封装了个run函数,供线程池工作线程调用时运行的。
1 | void addTask(stdcxx::shared_ptr<Runnable> task) { |
线程池管理ThreadManager
线程池的管理,包括增加工作线程worker,这个worker线程是继承自Runnable的,依附于具体的线程thread,还有就是增加任务,上面说到了server是怎么调用这个增加任务的接口的。注意worker和task都是继承自runnable,一个有依附的thread,一个没有,都要实现run函数。
thrift协议
thrift编解码过程
Thrift是一种用于定义RPC服务和数据交换格式的框架,其中编解码过程是其重要的组成部分。下面简单介绍一下Thrift的编解码过程:
- 定义IDL接口:使用Thrift的IDL语言进行服务接口定义,包括服务方法、参数和返回值的类型及名称等信息。
- 生成代码:使用Thrift提供的代码生成器根据IDL文件生成各语言环境下可用的客户端和服务端代码。
- 编写客户端和服务端:使用生成的代码进行客户端和服务端的开发。
- 序列化请求:客户端将请求参数序列化为二进制格式,以便在网络上传输。
- 发送请求:客户端通过网络发送请求消息。
- 接收请求:服务端接收请求消息。
- 反序列化请求:服务端将接收到的二进制数据反序列化为具体的参数类型。
- 处理请求:服务端根据请求消息调用对应的服务方法,并返回处理结果。
- 序列化响应:服务端将返回结果序列化为二进制格式,以便在网络上传输。
- 发送响应:服务端通过网络发送响应消息。
- 接收响应:客户端接收响应消息。
- 反序列化响应:客户端将接收到的二进制数据反序列化为具体的返回值类型。
序列化过程
Thrift的序列化过程可以分为两个步骤:写入(Write)和读取(Read)。对于一个需要序列化的对象,Thrift会按照其定义的类型和顺序依次将其转换为二进制数据。
Thrift支持多种序列化协议,常用的有: Binary、Compact、JSON。binary序列化是一种二进制的序列化方式。不可读,但传输效率高。
理解go语言编程-进阶话题
Go语言的反射实现了反射的大部分功能,但没有像Java语言那样内置类型工厂,故而无法做到像Java那样通过类型字符串创建对象实例。反射是把双刃剑,功能强大但代码可读性并不理想。若非必要,我们并不推荐使用反射。
Type为io.Reader,Value为MyReader{“a.txt”}。顾名思义,Type主要表达的是被反射的这个变量本身的类型信息,而Value则为该变量实例本身的信息。
1 | type MyReader struct { |
直接传递一个float到函数时,函数不能对外部的这个float变量有任何影响,要想有影响的话,可以传入该float变量的指针.
1 | var x float64 = 3.4 |
理解go语言编程-工程管理
Go语言明确宣告了拥护骆驼命名法而排斥下划线法。骆驼命名法在Java和C#中得到官方的支持和推荐,而下划线命名法则主要用在C语言的世界里,比如Linux内核和驱动开发上。
不带任何参数直接运行go fmt的话,可以直接格式化当前目录下的所有*.go文件,或者也可以指定一个GOPATH中可以找到的包名。
Go语言不仅允许我们导入本地包,还支持在语言级别调用远程的包。然后,在执行go build或者go install之前,只需要加这么一句: go get github.com/myteam/exp/crc32
1 | import ( |
当我们执行完go get之后,我们会在src目录中看到github.com目录,其中包含myteam/exp/crc32目录。在crc32中,就是该包的所有源代码。也就是说,go工具会自动帮你获取位于远程的包源码,在随后的编译中,也会在pkg目录中生成对应的.a文件。
对于Go语言本身来讲,远程包github.com/myteam/ exp/crc32只是一个与fmt无异的本地路径而已。
理解go语言编程-安全编程
采用单密钥的加密算法,我们称为对称加密。整个系统由如下几部分构成:需要加密的明文、加密算法和密钥。在加密和解密中,使用的密钥只有一个。常见的单密钥加密算法有DES、AES、RC4等。
采用双密钥的加密算法,我们称为非对称加密。整个系统由如下几个部分构成:需要加密的明文、加密算法、私钥和公钥。在该系统中,私钥和公钥都可以被用作加密或者解密,但是用私钥加密的明文,必须要用对应的公钥解密,用公钥加密的明文,必须用对应的私钥解密。常见的双密钥加密算法有RSA等。
哈希算法是一种从任意数据中创建固定长度摘要信息的办法。一般我们要求,对于不同的数据,要求产生的摘要信息也是唯一的。常见的哈希算法包括MD5、SHA-1等。
数字签名,是指用于标记数字文件拥有者、创造者、分发者身份的字符串。数字签名拥有标记文件身份、分发的不可抵赖性等作用。
A公司发布了一个可执行文件,称为AProduct.exe,A在AProduct.exe中加入了A公司的数字签名。A公司的数字签名是用A公司的私钥加密了AProduct.exe文件的哈希值,我们得到打过数字签名的AProduct.exe后,可以查看数字签名。这个过程实际上是用A公司的公钥解密了文件哈希值,从而可以验证两个问题:AProduct.exe是否由A公司发布,AProduct.exe是否被篡改。
我们登录某银行的网站,这时候网站会提示我们下载数字证书,否则将无法正常使用网银等功能。在我们首次使用U盾的时候,初始化过程即是向U盾中下载数字证书。那么,数字证书中包含什么呢?数字证书中包含了银行的公钥,有了公钥之后,网银就可以用公钥加密我们提供给银行的信息,这样只有银行才能用对应的私钥得到我们的信息,确保安全