系统级IO 每个进程都有个umask,通过umask函数来设置的,当进程通过带某个mode参数的open函数来创建一个新文件时,文件的访问权限位被设置为mode & ~umask,也就是umask是程序设定的掩码,哪怕你open时mode为777,最后出来的权限有可能不是777了。
共享文件:
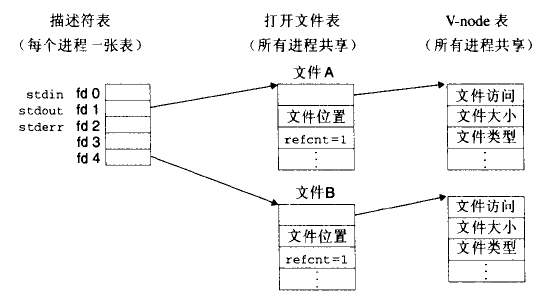
每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。
打开文件的集合是由一张文件表来表示的,所有进程共享这张表。文件表表项包括当前的文件位置、引用计数即当前指向该表项的描述符表项数,以及一个指向v-node表中对应表项的指针。引用计数变为0内核才会删除这个文件表项。
所有进程共享v-node表。表项包含stat结构中的大部分信息,如st_mode、st_size成员。
IO重定向:
1 2 #include <unistd.h> int dup2 (int oldfd, int newfd)
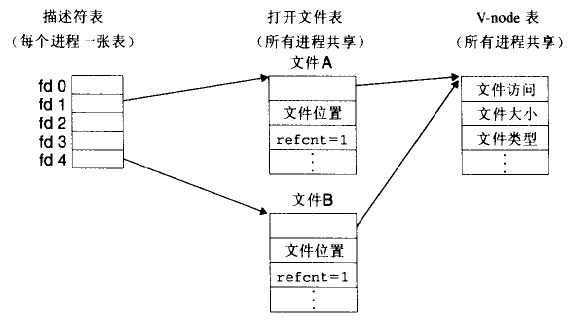
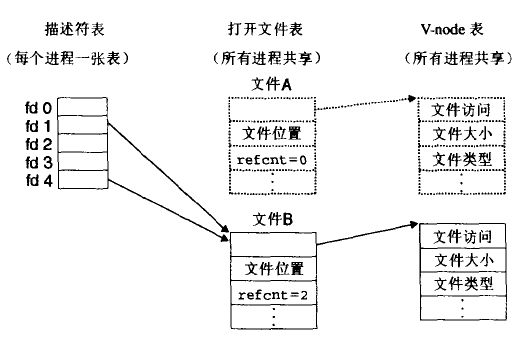
dup2函数拷贝描述符表项oldfd到描述符表表项newfd,覆盖描述符表表项newfd以前的内容。如果newfd已经打开了,dup2会在拷贝oldfd之前关闭newfd。下图描述符1(标准输出)对应文件A(比如是一个终端),描述符4对应文件B(比如是一个磁盘文件),最开始时A和B的引用计数都为1,调用dup2(4,1)后,两个描述符都指向B,也就是第一个参数是重定向的目的地,文件A已经被关闭了,不再有标准输出了,并且它的文件表和v-node表表项也已经删除了。文件B(目的地那个)的引用计数已经增加了,以后写到标准输出的数据都被重定向到文件B。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "csapp.h" int main () int fd1, fd2; char c; fd1 = Open ("foobar.txt" , O_RDONLY, 0 ); fd2 = Open ("foobar.txt" , O_RDONLY, 0 ); Read (fd2, &c, 1 ); Dup2 (fd2, fd1); Read (fd1, &c, 1 ); printf ("c = %c\n" , c); exit (0 ); }
标准IO:
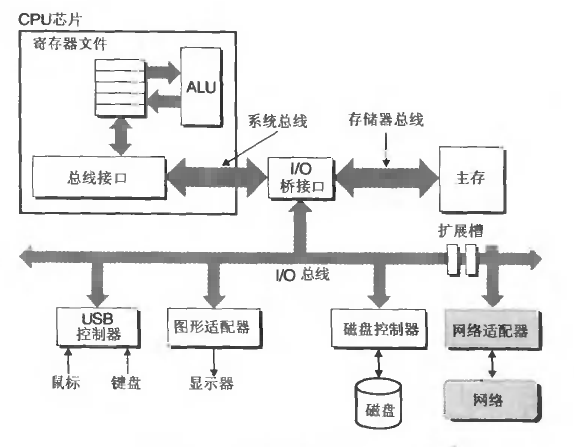
网络编程 一个网络主机的硬件组成。
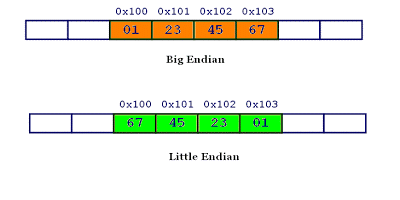
1 2 3 4 5 6 7 8 9 10 11 12 #include <iostream> int main () unsigned int num = 1 ; char *p = reinterpret_cast <char *>(&num); if (*p) { std::cout << "Little Endian" << std::endl; } else { std::cout << "Big Endian" << std::endl; } return 0 ; }
网络字节序和主机字节序转换方法:
1 2 3 4 5 6 7 #include <netinet/in.h> unsigned long int htonl (unsigned long int hostlong) unsigned short int htons (unsigned short int hostshort) unsigned long int ntohl (unsigned long int netlong) unsigned short int ntohs (unsigned short int netshort)
ip地址与点分十进制串之间的转换:
1 2 3 4 5 #include <arpa/inet.h> int inet_aton (const char *cp, struct in_addr *inp) char *inet_ntoa (struct in_addr in)
可以调用gethostbyname和gethostbyaddr函数,从DNS数据库中检索任意的主机条目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct hostent { char *h_name; char **h_aliases; int h_addrtype; int h_length; char **h_addr_list; } #include <netdb.h> struct hostent *gethostbyname (const char *name);struct hostent *gethostbyaddr (const void *addr, socklen_t len, int type);
网络套接字接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ telnet nephen.cn 80 Trying 110.40.194.189... Connected to nephen.cn. Escape character is '^]' . GET / HTTP/1.1 Host: nephen.cn HTTP/1.1 301 Moved Permanently Server: nginx/1.21.6 Date: Thu, 16 Feb 2023 09:43:02 GMT Content-Type: text/html Content-Length: 169 Connection: keep-alive Location: https://nephen.cn/ <html> <head ><title>301 Moved Permanently</title></head> <body> <center><h1>301 Moved Permanently</h1></center> <hr><center>nginx/1.21.6</center> </body> </html>
代理缓存中会使用Host报头,指示了原始服务器的域名。响应报头重要的是Content-Type以及Content-Length。
CGI服务器
1 2 3 4 5 6 if (fork() == 0 ) { setenv("QUERY_STRING" , "15000&213" , 1 ); dup2(fd, STDOUT_FILNO); execve(filename, emptylist, environ); } wait(NULL );
Nginx不支持对外部程序的直接调用或者解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在Linux下是socket,(这个socket可以是文件socket,也可以是ip socket)。为了调用CGI程序,还需要一个FastCGI的wrapper(wrapper可以理解为用于启动另一个程序的代理服务程序),这个wrapper绑定在某个固定socket上,如端口或者文件socket。当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper代理服务程序接纳到请求,然后派生出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着wrapper代理服务程序再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据发送给客户端,这就是Nginx+FastCGI的整个运作过程。详细的过程,如图所示
1 2 3 4 5 6 location ~* \.php$ { fastcgi_pass 127.0.0.1:9000; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; #文档路径 fastcgi_param PATH_INFO $fastcgi_script_name; # 脚本名 include fastcgi_params; }
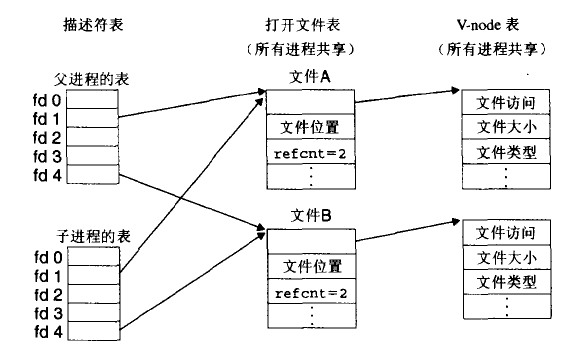
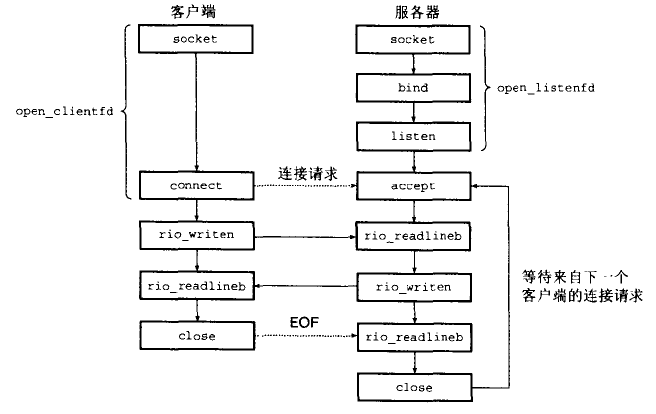
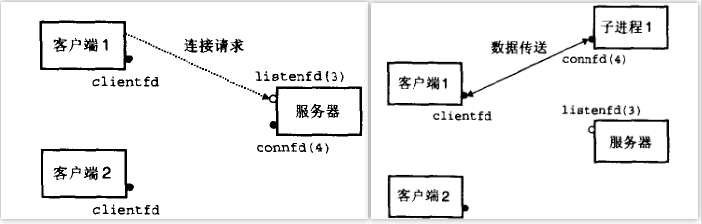
并发编程 基于进程的并发服务器:子进程需要关闭它的监听描述符3,因为父子进程的已连接描述符都指向同一个文件表表项,父进程需要关闭它的已连接描述符4,否则永不会释放已连接描述符4的文件表条目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void sigchld_handler (int sig) { while (waitpid(-1 , 0 , WNOHANG) > 0 ); return ; } Signal(SIGCHLD, sigchld_handler); while (1 ) { connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); if (Fork() == 0 ) { Close(listenfd); echo(connfd); Close(connfd); exit (0 ); } Close(connfd); }
IO多路复用:
1 2 3 4 5 6 7 8 9 10 11 12 13 FD_SET(STDIN_FILENO, &read_set); FD_SET(listenfd, &read_set); while (1 ) { ready_set = read_set; Select(listenfd+1 , &ready_set, NULL , NULL , NULL ); if (FD_ISSET(STDIN_FILENO, &ready_set)) command(); if (FD_ISSET(listenfd, &ready_set)) { connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen); echo(connfd); } }
更细粒度的多路复用(有限状态机模型):单一进程,某个逻辑流阻塞,其他流就不可能有进展,http://csapp.cs.cmu.edu/2e/ics2/code/src/csapp.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 typedef struct { int maxfd; fd_set read_set; fd_set ready_set; int nready; int maxi; int clientfd[FD_SETSIZE]; rio_t clientrio[FD_SETSIZE]; } pool; listenfd = open_lestenfd(port); init_pool(listenfd, &pool); while (1 ) { pool.ready_set = pool.read_set; pool.nready = Select(pool.maxfd+1 , &pool.ready_set, NULL , NULL , NULL ); if (FD_ISSET(listenfd, &pool.ready_set)) { connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen); add_client(connfd, &pool); } check_clients(&pool); } void init_pool (int listenfd, pool *p) { p->maxi = -1 ; for (int i = 0 ; i < FD_SETSIZE; i++) { p->clientfd[i] = -1 ; } p->maxfd = listenfd; FD_ZERO(&pool.read_set); FD_SET(listenfd, &p->read_set); } void add_client (int connfd, pool *p) { p->nready--; for (int i = 0 ; i < FD_SETSIZE; i++) { if (p->clientfd[i] < 0 ) { p->clientfd[i] = connfd; Rio_readinitb(&p->clientrio[i], connfd); FD_SET(connfd, &p->read_set); if (connfd > p->maxfd) { p->maxfd = connfd; } if (i > p->maxi) { p->maxi = i; } break ; } } if (i == FD_SETSIZE) { app_error("add_client error: Too many clients" ); } } void check_clients (pool *p) { int connfd, n; char buf[MAXLINE]; rio_t rio; for (int i = 0 ; (i <= p->maxi) && (p->nready > 0 ); i++) { connfd = p->clientfd[i]; rio = p->clientrio[i]; if ((connfd > 0 ) && (FD_ISSET(connfd, &p->ready_set))) { p->nready--; if ((n = Rio_readline(&rio, buf, MAXLINE)) != 0 ) { byte_cnt += n; printf ("Server received %d (%d total) bytes on fd %d\n" , n, byte_cnt, connfd); Rio_write(connfd, buf, n); } } else { Close(connfd); FD_CLR(connfd, &p->read_set); p->clients[i] = -1 ; } } }
基于线程并发编程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 listenfd = open_listenfd(port); while (1 ) { connfdp = Malloc(sizeof (int )); *connfdp = Accept(listenfd, (SA *)&clientaddr, &clientlen); Pthread_create(&tid, NULL , thread, connfdp); } void *thread (void *vargp) { int connfd = *(int *)vargp; Pthread_detach(pthread_self()); Free(vargp); echo(connfd); Close(connfd); return NULL ; }
posix标准定义了许多操作信号量的函数。三个基本的操作是sem_init、sem_wait(P操作)和sem_post(V操作),P(Prtoberen测试)/V(Verhogen增加)。
1 2 3 4 5 sem_t mutex;sem_init(&mutex, 0 , 1 ); P(&mutex); Cnt++; V(&mutext);
如果对于程序中每对互斥锁(s,t),每个既包含s也包含t的线程都按相同的顺序同时对它们加锁,那么这个程序是无死锁的。